30 Lists and Attributes
The next important data type in our journey through R is the list. Lists are quite similar to vectors—they are ordered collections of data, indexable by index number, logical vector, and name (if the list is named). Lists, however, can hold multiple different types of data (including other lists). Suppose we had three different vectors representing some information about the plant Arabidopsis thaliana.

We can then use the list() function to gather these vectors together into a single unit with class "list".

Graphically, we might represent this list like so:

Here, the [1] syntax is indicating that the elements of the list are vectors (as in when vectors are printed). Like vectors, lists can be indexed by index vector and logical vector.

Both of the above assign to the variable sublist a list looking like:

This seems straightforward enough: subsetting a list with an indexing vector returns a smaller list with the requested elements. But this rule can be deceiving if we forget that a vector is the most basic element of data. Because 2 is the length-one vector c(2), athal[2] returns not the second element of the athal list, but rather a length-one list with a single element (the vector of ecotypes).

A graphical representation of this list:

We will thus need a different syntax if we wish to extract an individual element from a list. This alternate syntax is athal[[2]].

If we wanted to extract the second ecotype directly, we would need to use the relatively clunky second_ecotype <- athal[[2]][2], which accesses the second element of the vector (accessed by [2]) inside of the of the second element of the list (accessed by [[2]]).

When we print a list, this structure and the double-bracket syntax is reflected in the output.

Named Lists, Lists within Lists
Like vectors, lists can be named—associated with a character vector of equal length—using the names() function. We can use an index vector of names to extract a sublist, and we can use [[]] syntax to extract individual elements by name.

We can even extract elements from a list if the name of the element we want is stored in another variable, using the [[]] syntax.

As fun as this double-bracket syntax is, because extracting elements from a list by name is a common operation, there is a shortcut using $ syntax.

In fact, if the name doesn’t contain any special characters (spaces, etc.), then the quotation marks can be left off.

This shortcut is widely used and convenient, but, because the quotes are implied, we can’t use $ syntax to extract an element by name if that name is stored in an intermediary variable. For example, if extract_name <- "ecotypes", then athal$extract_name will expand to athal[["extract_name"]], and we won’t get the ecotypes vector. This common error reflects a misunderstanding of the syntactic sugar employed by R. Similarly, the $ syntax won’t work for names like "# Chromosomes" because that name contains a space and a special character (for this reason, names of list elements are often simplified).
Frequently, $ syntax is combined with vector syntax if the element of the list being referred to is a vector. For example, we can directly extract the third ecotype, or set the third ecotype.

Continuing with this example, let’s suppose we have another list that describes information about each chromosome. We can start with an empty list, and assign elements to it by name.
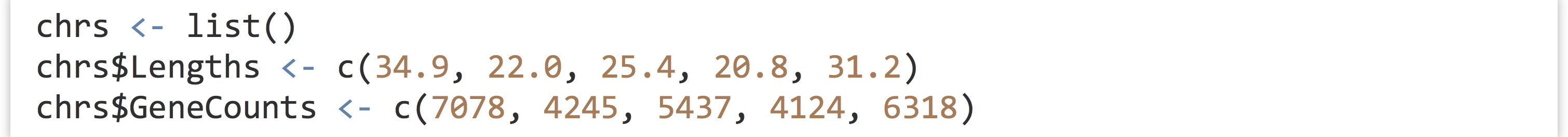
This list of two elements relates to A. thaliana, so it makes sense to include it somehow in the athal list. Fortunately, lists can contain other lists, so we’ll assign this chrs list as element of the athal list.

Lists are an excellent container for general collections of heterogeneous data in a single organized “object.” (These differ from Python objects in that they don’t have methods stored in them as well, but we’ll see how R works with methods in later chapters.) If we ran print(athal) at this point, all this information would be printed, but unfortunately in a fairly unfriendly manner:

This output does illustrate something of interest, however. We can chain the $ syntax to access elements of lists and contained lists by name. For example, lengths <- athal$ChrInfo$Lengths extracts the vector of lengths contained in the internal ChrInfo list, and we can even modify elements of these vectors with syntax like athal$ChrInfo$GeneCounts[1] <- 7079 (perhaps a new gene was recently discovered on the first chromosome). Expanding the syntax a bit to use double-brackets rather than $ notation, these are equivalent to lengths <- athal[["ChrInfo"]][["Lengths"]] and athal[["ChrInfo"]][["GeneCounts"]][1] <- 7079.
Attributes, Removing Elements, List Structure
Lists are an excellent way to organize heterogeneous data, especially when data are stored in a Name → Value association,[1] making it easy to access data by character name. But what if we want to look up some information associated with a piece of data but not represented in the data itself? This would be a type of “metadata,” and R allows us to associate metadata to any piece of data using what are called attributes. Suppose we have a simple vector of normally distributed data:
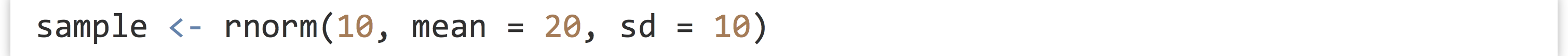
Later, we might want know what type of data this is: is it normally distributed, or something else? We can solve this problem by assigning the term "normal" as an attribute of the data. The attribute also needs a name, which we’ll call "disttype". Attributes are assigned in a fashion similar to names.

When printed, the output shows the attributes that have been assigned as well.

We can separately extract a given attribute from a data item, using syntax like sample_dist <- attr(sample, "disttype"). Attributes are used widely in R, though they are rarely modified in day-to-day usage of the language.[2]
To expand our A. thaliana example, let’s assign a “kingdom” attribute to the species vector.

At this point, we’ve built a fairly sophisticated structure: a list containing vectors (one of which has an attribute) and another list, itself containing vectors, with the various list elements being named. If we were to run print(athal), we’d see rather messy output. Fortunately, R includes an alternative to print() called str(), which nicely prints the structure of a list (or other data object). Here’s the result of calling str(athal) at this point.

Removing an element or attribute from a list is as simple as assigning it the special value NULL.
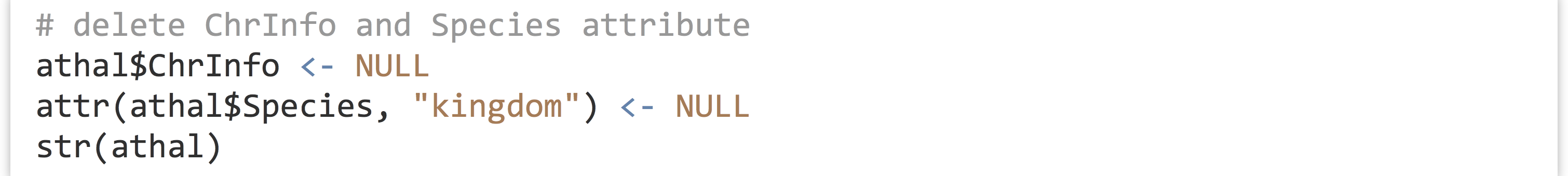
The printed structure reveals that this information has been removed.

What is the point of all this detailed list making and attribute assigning? It turns out to be quite important, because many R functions return exactly these sorts of complex attribute-laden lists. Consider the t.test() function, which compares the means of two vectors for statistical equality:
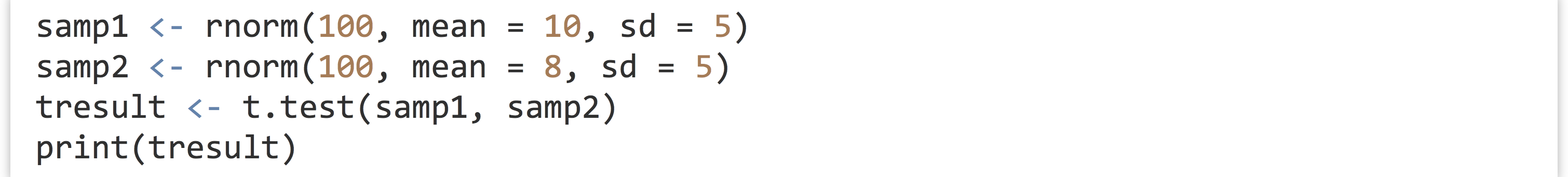
When printed, the result is a nicely formatted, human-readable result.

If we run str(tresult), however, we find the true nature of tresult: it’s a list!

Given knowledge of this structure, we can easily extract specific elements, such as the p value with pval <- tresult$p.value or pval <- tresult[["p.value"]].
One final note about lists: vectors (and other types) can be converted into a list with the as.list() function. This will come in handy later, because lists are one of the most general data types in R, and we can use them for intermediary data representations.

Exercises
- The following code first generates a random sample called
a, and then a sample calledresponse, wherein each element ofresponseis an element ofatimes 1.5 plus some random noise: Next, we can easily create a linear model predicting values of
Next, we can easily create a linear model predicting values of responsefroma: When printed, the output nicely describes the parameters of the model.
When printed, the output nicely describes the parameters of the model. We can also easily test the significance of the parameters with the
We can also easily test the significance of the parameters with the anova()function (to run an analysis of variance test on the model). The output again shows nicely formatted text:
The output again shows nicely formatted text: From the
From the model, extract the coefficient ofainto a variable calleda_coeff(which would contain just the number1.533367for this random sample).Next, fromvartestextract the p value associated with theacoefficient into a vector calleda_pval(for this random sample, the p value is2.2e-16). - Write a function called
simple_lm_pval()that automates the process above; it should take two parameters (two potentially linearly dependent numeric vectors) and return the p value associated with the first (nonintercept) coefficient. - Create a list containing three random samples from different distributions (e.g., from
rnorm(),runif(), andrexp()), and add an attribute for"disttype"to each. Useprint()andstr()on the list to examine the attributes you added. - Some names can be used with
$notation without quotation marks; ifl <- list(values = c(20, 30)), thenprint(l$values)will print the internal vector. On the other hand, ifl <- list("val-entries" = c(20, 30)), then quotations are required as inprint(l$"val-entries"). By experimentation, determine at least five different characters that require the use of quotation marks when using$notation. - Experiment with the
is.list()andas.list()functions, trying each of them on both vectors and lists.
- R lists are often used like dictionaries in Python and hash tables in other languages, because of this easy and effective Name → Value lookup operation. It should be noted that (at least as of R 3.3), name lookups in lists are not as efficient as name lookups in Python dictionaries or other true hash tables. For an efficient and more idiomatic hash table/dictionary operation, there is also the package
hashavailable for install withinstall.packages("hash"). ↵ - For example, the names of a vector are stored as an attribute called “names”—the lines
names(scores) <- c("Student A", "Student B", "Student C")andattr(scores, "names") <- c("Student A", "Student B", "Student C")are (almost) equivalent. Still, it is recommended to use specialized functions likenames()rather than set them withattr()because thenames()function includes additional checks on the sanity of the names vector. ↵
