25 Algorithms and Data Structures
Having learned so many programming concepts—variables and the data to which they refer, functions, loops, and so on—it would be a shame not to talk about some of the surprising and elegant methods they enable. Computer science students spend years learning about these topics, and the themes in this chapter underlie much of bioinformatics.
We’ll start with algorithms, which according to a classic book on the topic—Introduction to Algorithms by Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein—are:
any well-defined computational procedure that takes some value, or set of values, as input and produces some value, or set of values, as output.
With such a broad definition, all of the Python coding we’ve done could accurately be categorized as practice in algorithms. The word “algorithm,” by the way, derives from the name of the eighth-century Persian mathematician al-Khwārizmī, who developed systematic approaches for solving equations (among other accomplishments). Although most functioning code may be characterized as an algorithm, algorithms usually involve more than just collating data and are paired with well-defined problems, providing a specification for what valid inputs are and what the corresponding outputs should be. Some examples of problems include:
- Given a list of
 numbers in arbitrary order, return it or a copy of it in sorted order. (The “sorting” problem.)
numbers in arbitrary order, return it or a copy of it in sorted order. (The “sorting” problem.) - Given a list of numbers in sorted order and a query number
q, returnTrueifqis present in the list andFalseif it is not. (The “searching” problem.) - Given two strings of length
 and, line them up against each other (inserting dashes where necessary to make them the same length) to maximize a score based on the character matches. (The “string alignment” problem.)
and, line them up against each other (inserting dashes where necessary to make them the same length) to maximize a score based on the character matches. (The “string alignment” problem.)
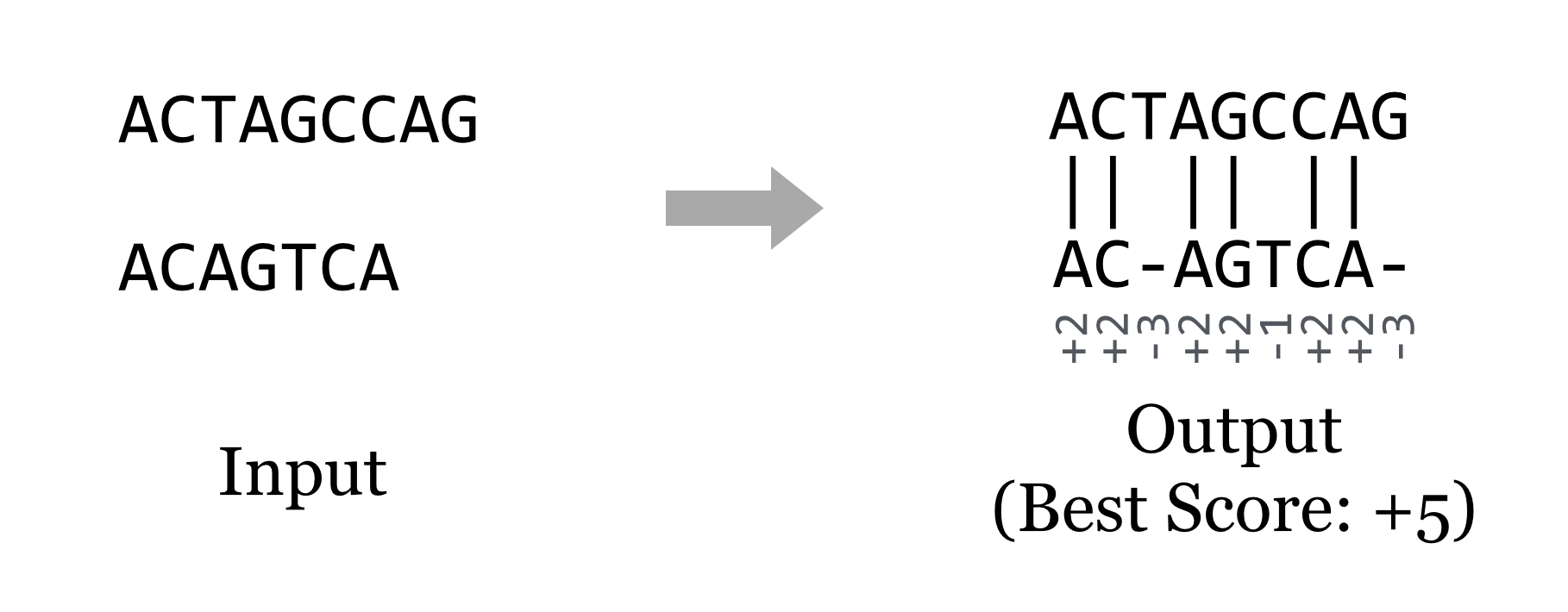
Clearly, some problems, like the string alignment problem, are of special interest for life scientists. Others, like sorting and searching, are ubiquitous. No matter who cares about the problem, a good algorithm for solving it should do so efficiently. Usually, “efficiently” means “in a short amount of time,” though with the large data sets produced by modern DNA-sequencing technologies, it often also means “using a small amount of memory.”
Most bioinformatics problems like string alignment require rather sophisticated methods built from simpler concepts, so we’ll start with the usual introductory topic for algorithms design and analysis: sorting. After all, someone had to write Python’s sorted() function for lists, and it does form a good basis for study.
Consider a small list of five numbers, in unsorted order.
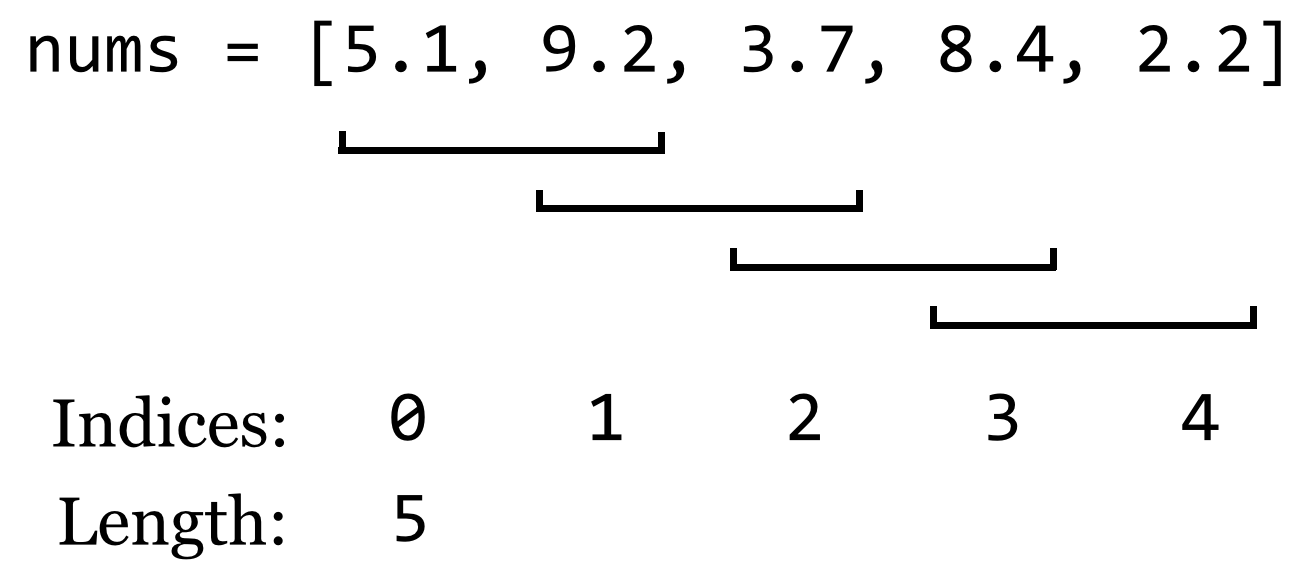
What code might we write to sort these numbers? Whatever it is, it might make sense to put it into a function that takes an unsorted list, and returns a copy of it in sorted order (to stay consistent with Python’s use of the principle of command-query separation). To start, we’ll make a copy of the list, and then we’ll have the function merely “fix up” some of the out-of-order numbers in this copy by looking at a sliding window of size 2—pairs of adjacent numbers—and switching their placement if they are out of order.

Just fixing up a handful of pairs in this way won’t result in the list being sorted, but it should be obvious that because the pairs of fix-ups overlap, the largest number will have found its way to the last position. In a sense, it “bubbled” to the top. If we were to repeat this process, the second-to-largest number must also find its way to the correct spot. In fact, if we repeat this process as many times as there are numbers, the list will be fully sorted.

This algorithm for sorting is affectionately known as “bubblesort.” In a rough sense, how many operations will this algorithm perform, in the worst case, for a list of size? Suppose the if-statement always finds True, and numbers need to be swapped. In this case, each operation of the inner loop requires five or so “time steps” (four assignments and an if check). The inner loop runs  times (if there are numbers), which is itself repeated times in the outer loop. The copy step to produce the new
times (if there are numbers), which is itself repeated times in the outer loop. The copy step to produce the new c_nums list also uses steps, so the total number of basic operations is, more or less,
![\[n(n-1)5 + n = 5n^{\textcolor{white}{\hat{\textcolor{black}{2}}}} - 4n\ .\]](https://open.oregonstate.education/app/uploads/quicklatex/quicklatex.com-075e977d783bf5e4287434107a1f374d_l3.png "Rendered by QuickLaTeX.com")
When analyzing the running time of an algorithm, however, we only care about the “big stuff.”
Order Notation
In computing an algorithm’s run time, we only care about the highest-order terms, and we tend to ignore constants that aren’t related to the “size” of the input. We say that the run time is order of the highest-order term (without constants), which we denote with an uppercase :
: is
is 
We read this as “five squared minus four is order squared” or “five squared minus four is big-oh squared.” Because this run time talks about a particular algorithm, we might also say “bubblesort is order squared.” Big-O notation implies that, roughly, an algorithm will run in time less than or equal to the equation interpreted as a function of the input size, in the worst case (ignoring constants and small terms).
Worst-case analysis assumes that we get unlucky with every input, but in many cases the algorithm might run faster in practice. So, why do we do worst-case analysis? First, it gives the user of an algorithm a guarantee—nobody wants to hear that software might use a certain amount of time. Second, while it is sometimes possible to do average-case analysis, it requires knowledge of the distribution of input data in practice (which is rare) or more sophisticated analysis techniques.
Why do we use order notation to characterize algorithm run time, dropping small terms and constants? First, although we stated previously that each basic operation is one “computer step,” that’s not really true: the line c_nums[index + 1] = leftnum requires both an addition and an assignment. But no one wants to count each CPU cycle individually, especially if the result won’t change how we compare two algorithms for large data sets, which is the primary purpose of order notation. Dropping off constant terms and lower-order terms makes good mathematical sense in these cases. For large enough input (i.e., all greater than some size ), even terms that seem like they would make a big difference turn out not to matter, as the following hypothetical comparison demonstrates.
), even terms that seem like they would make a big difference turn out not to matter, as the following hypothetical comparison demonstrates.
![\[ \begin{aligned} 0.01n^{\textcolor{white}{\hat{\textcolor{black}{2}}}} - 100n &> 200n^{\textcolor{white}{\hat{\textcolor{black}{1.5}}}} + 20n, \text{for } n > \text{some } c, \\ O(n^{2}) &>O(n^{1.5}), \\ \text{Time Alg A} &> \text{Time Alg B (for large inputs).} \end{aligned} \]](https://open.oregonstate.education/app/uploads/quicklatex/quicklatex.com-878e41ecf9044ca965731c1bb0c800bc_l3.png "Rendered by QuickLaTeX.com")
(Technically in the above  is an abuse of notation; we should say
is an abuse of notation; we should say  is
is  based on the definition of the notation.) In this case,
based on the definition of the notation.) In this case,  is larger than
is larger than  when is larger than 400,024,000 (which is this example’s).
when is larger than 400,024,000 (which is this example’s).
So, although order notation seems like a fuzzy way of looking at the efficiency of an algorithm, it’s a rigorously defined and reasonable way to do so.[1] Because some programming languages are faster than others—but only by a constant factor (perhaps compiled C code is 100 times faster than Python)—a good algorithm implemented in a slow language often beats a mediocre algorithm implemented in a fast language!
Now, a run time of isn’t very good: the time taken to sort a list of numbers will grow quadratically with the size of the list.
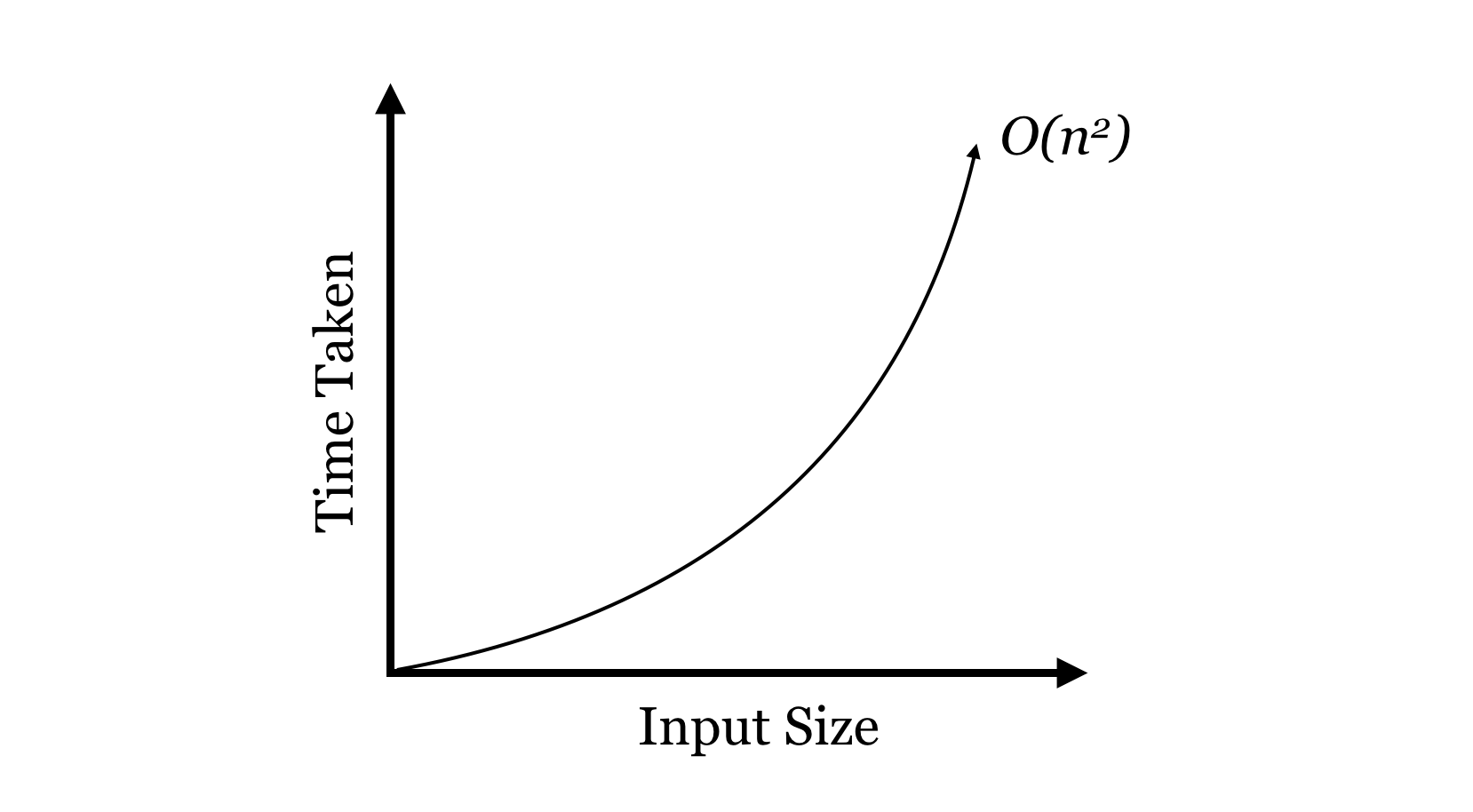
isn’t great, but for the sorting problem we can do better, and we’ll return to the study of algorithms and sorting a bit later. First, let’s detour and talk about interesting ways we can organize data, using variables and the objects to which they refer.
Data Structures
A data structure is an organization for a collection of data that ideally allows for fast access and certain operations on the data. We’ve seen a couple of data structures already in Python: lists and dictionaries. Given such a structure, we might ask questions like:
- Does the data structure keep its elements in a specific order (such as sorted order)? If we use
.append()to add elements to lists, lists are kept in the order items are added. If we wanted the list to stay sorted, we’d have to ensure new elements are inserted in right spot. - How long does it take to add a new element? For Python lists, the
.append()method operates in time , which is to say a single element can be added to the end, and the time taken does not depend on how big the list is. Unfortunately, this won’t be true if we need to keep the list sorted, because inserting into the middle requires rearranging the way the data are stored.
, which is to say a single element can be added to the end, and the time taken does not depend on how big the list is. Unfortunately, this won’t be true if we need to keep the list sorted, because inserting into the middle requires rearranging the way the data are stored. - How long does it take to find the smallest element? Because using
.append()adds elements to the end of the list, unless we keep the list sorted, we need to search the entire list for the smallest element. This operation takes time , where is the length of the list. If the list is sorted, though, it takes only time to look at the front of it.
, where is the length of the list. If the list is sorted, though, it takes only time to look at the front of it.
There are trade-offs that we can make when thinking about how to use data structures. Suppose, for example, that we wanted to quickly find the smallest element of a list, even as items are added to it. One possibility would be to sort the list after each addition; if we did that, then the smallest element would always be at index 0 for quick retrieval. But this is a lot of work, and the total time spent sorting would start to outweigh the benefits of keeping the list sorted in the first place! Even better, we could write a function that (1) inserts the new item to the end and then (2) bubbles it backward to its correct location; only one such bubbling would be needed for each insertion, but each is an operation (unless we could somehow guarantee that only large elements are added).

Finding the smallest item is easy, as we know it is always present at index 0.
| Structure | Insert an Item | Get Smallest |
|---|---|---|
| Sorted Simple List | |
|
Instead, let’s do something much more creative, and build our own data structure from scratch. While this data structure is a lot of trouble to create for only a little benefit, it does have its uses and serves as a building block for many other sophisticated structures.
Sorted Linked Lists
Our data structure, called a “sorted linked list,” will keep a collection of items in sorted order, and will do the work of inserting new items in the correct location in that order. These items could be integers, floats, or strings, anything that can be compared with the < operator (which, recall, compares strings in lexicographic order; as discussed in previous chapters, we can even define our own object types that are comparable with > by implementing .__lt__(), .__eq__() and similar methods).
To accomplish this task, we’re going to make heavy use of classes and objects, and the fact that a variable (even an instance variable) is a name that refers to an object.
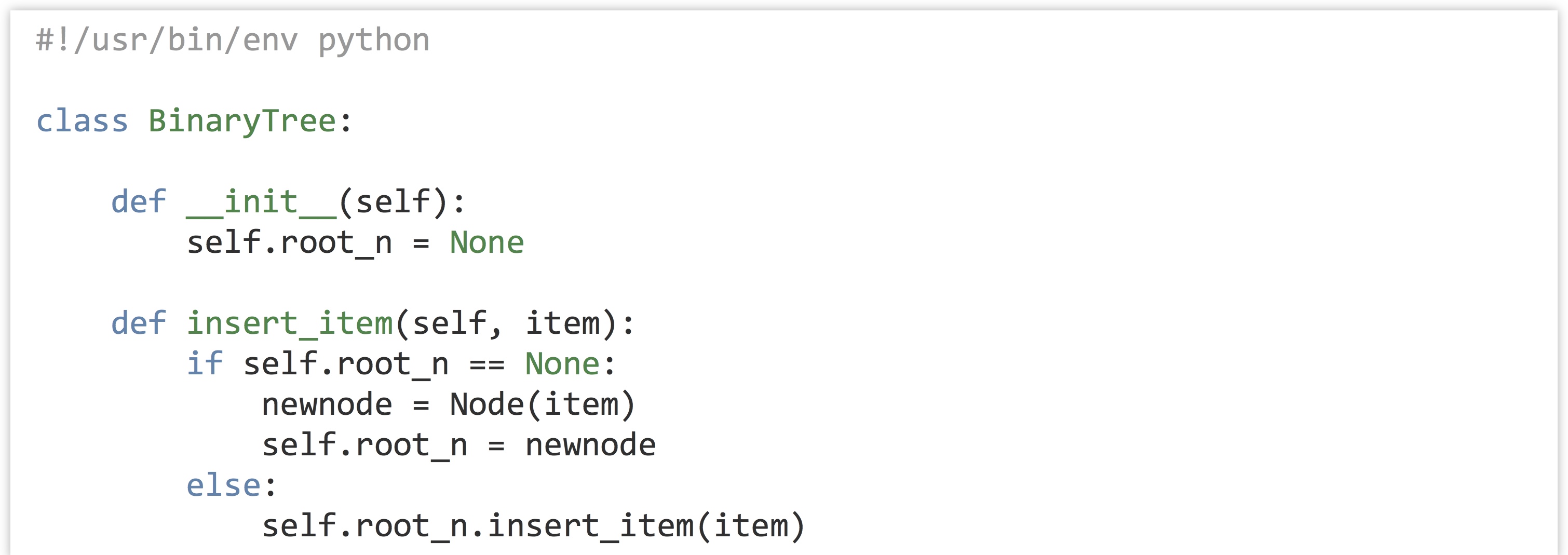
The strategy will be to have two types of objects: the first, which we’ll call a LinkedList, will be the main type of object with which our programs will interact (much like we interacted with Chromosome objects in previous chapters, while SNP objects were dealt with by the Chromosome objects). The LinkedList object will have methods like .insert_item() and .get_smallest(). The other objects will be of type Node, and each of these will have an instance variable self.item that will refer to the item stored by an individual Node. So, drawing just the objects in RAM, our sorted linked list of three items (4, 7, and 9) might look something like this:
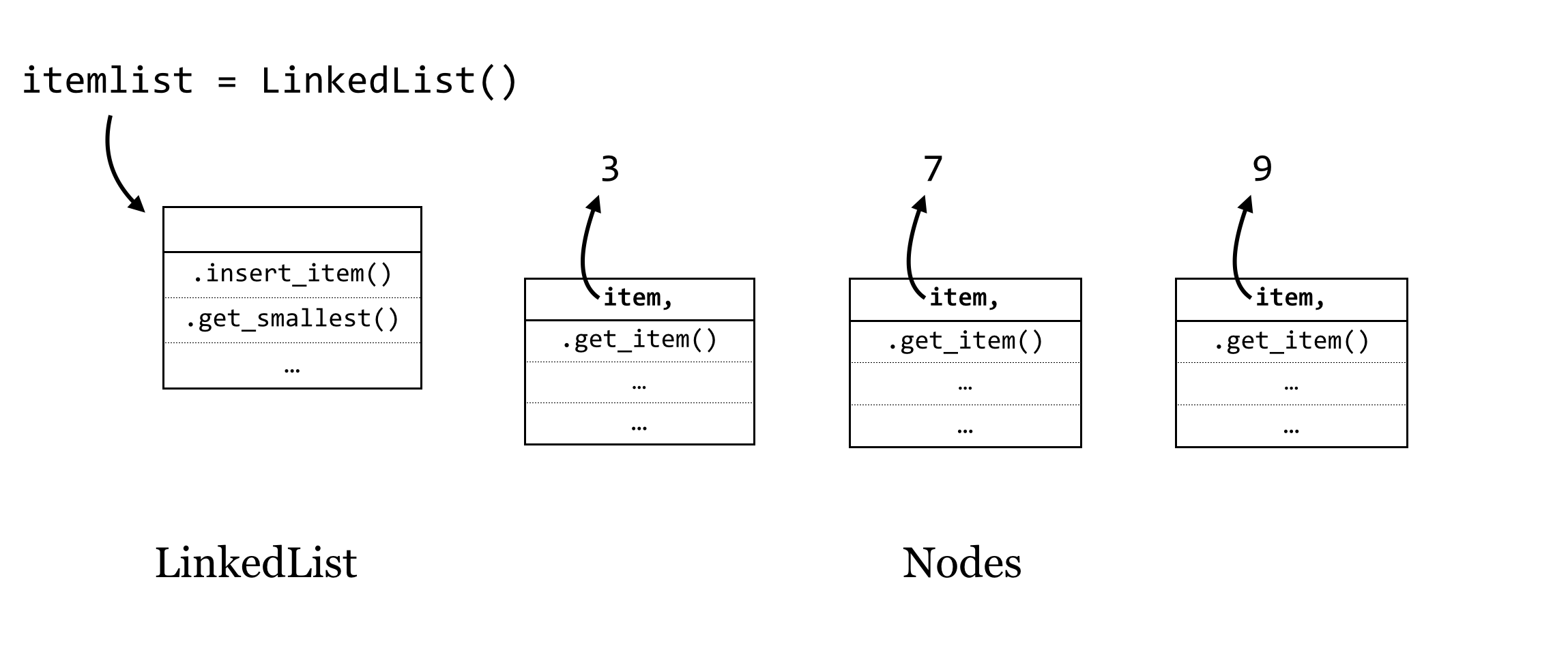
(The objects are unlikely to be neatly organized this way in RAM—we’re showing them in a line for illustration only.) The arrows in this figure indicate that after we create a new LinkedList object called itemlist, this variable is a name that refers to an object, and each Node object has a self.item instance variable that refers to a “data” object of some type, like an integer or string.[2]
Now, if this collection of objects were to exist as shown, it wouldn’t be that useful. Our program would only be able to interact with the itemlist object, and in fact there are no variables that refer to the individual Node objects, so they would be deleted via garbage collection.
Here’s the trick: if an instance variable is just a variable (and hence a reference to an object), we can give each Node object a self.next_n instance variable that will refer to the next node in line. Similarly, the LinkedList object will have a self.first_n instance variable that will refer to the first one.
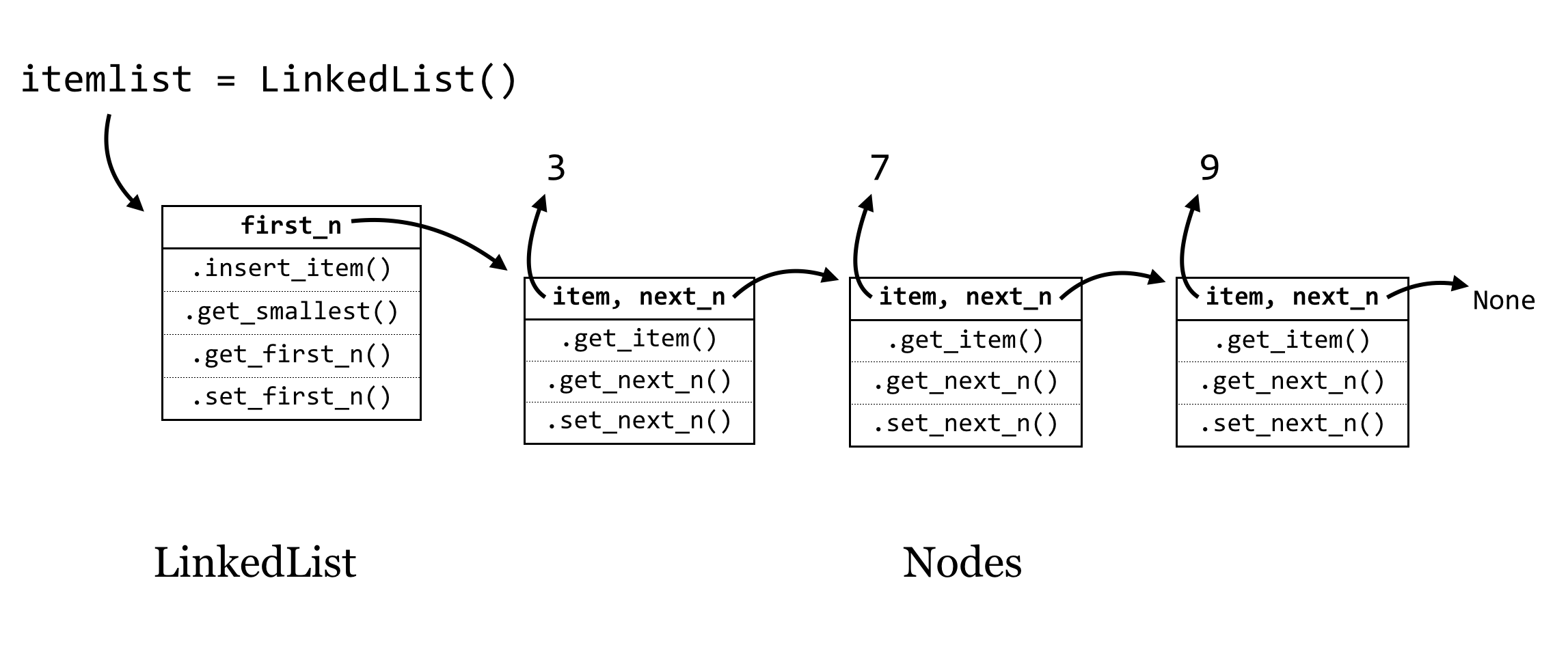
The last Node object’s self.next_n refers to None, a placeholder that we can use to allow a variable to reference “nothing here.” Actually, None will be the initial value for self.next_n when a new node is created, and we’ll have to add methods for get_next_n() and set_next_n() that allow us to get or change a Node’s next_n variable at will. The LinkedLists’s first_n variable will similarly be initialized as None in the constructor.
Suppose that we have this data structure in place, and we want to add the number 2; this would be the new “smallest” item. To do this we’d need to run itemlist.insert_item(2), and this method would consider the following questions to handle all of the possible cases for inserting an item (by using if-statements):
- Is
self.first_nequal toNone? If so, then the new item is the only item, so create a newNodeholding the new item and setself.first_nto that node. - If
self.first_nis not equal toNone:- Is the new item smaller than
self.first_n’s item? If so, then (1) create a newNodeholding the new item, (2) set itsnext_ntoself.first_n, and then (3) setself.first_nto the new node. Here’s an illustration for this case: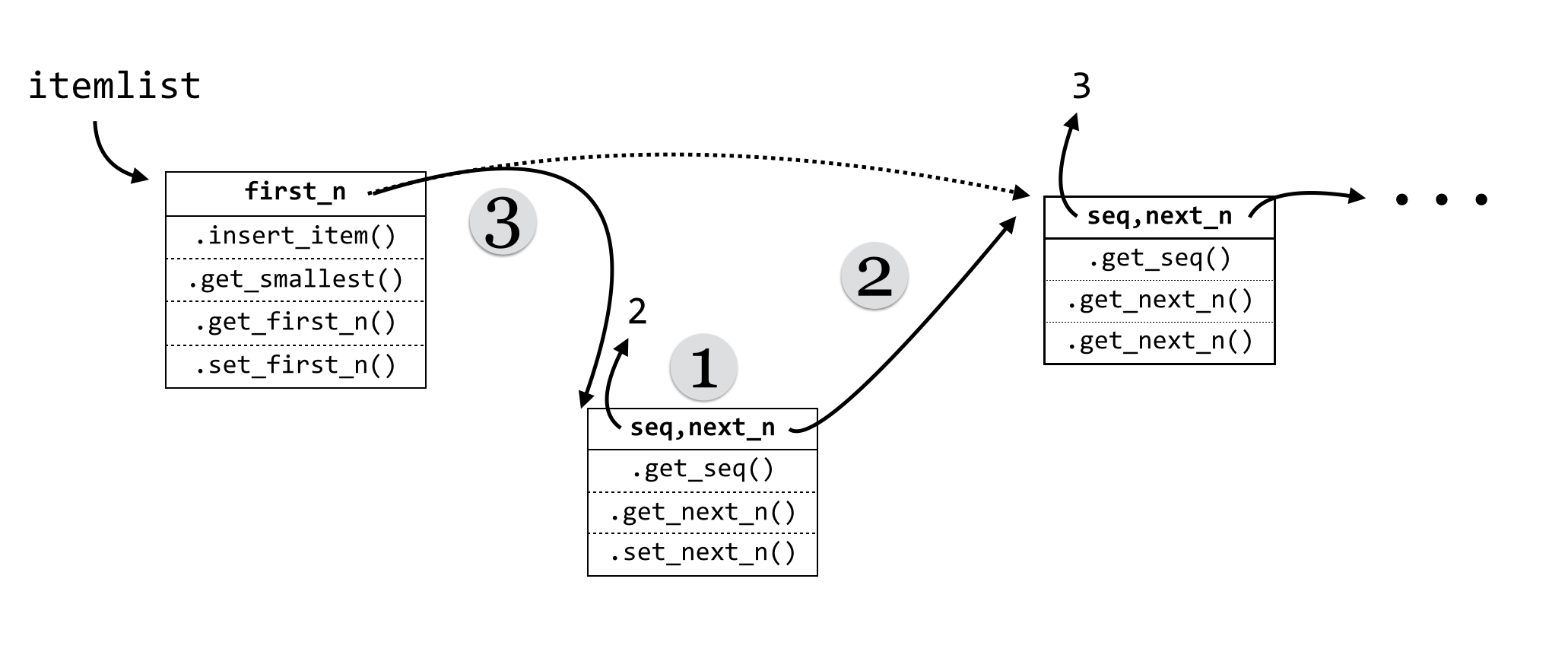
- Otherwise, the new node does not go between the
LinkedListobject and the firstNodeobject. In this case, we could treat theself.first_nobject as though it were itself aLinkedList, if only it had an.insert_item()method.
- Is the new item smaller than
This case (b) is really the heart of the linked list strategy: each Node object will also have an .insert_item() method. Further, each node’s insert_item() will follow the same logic as above: if self.next_n is None, the new node goes after that node. If not, the node needs to determine if the new node should go between itself and the next node, or if it should “pass the buck” to the node next in line.
Now we can turn to the code. First, here’s the code for the LinkedList class.
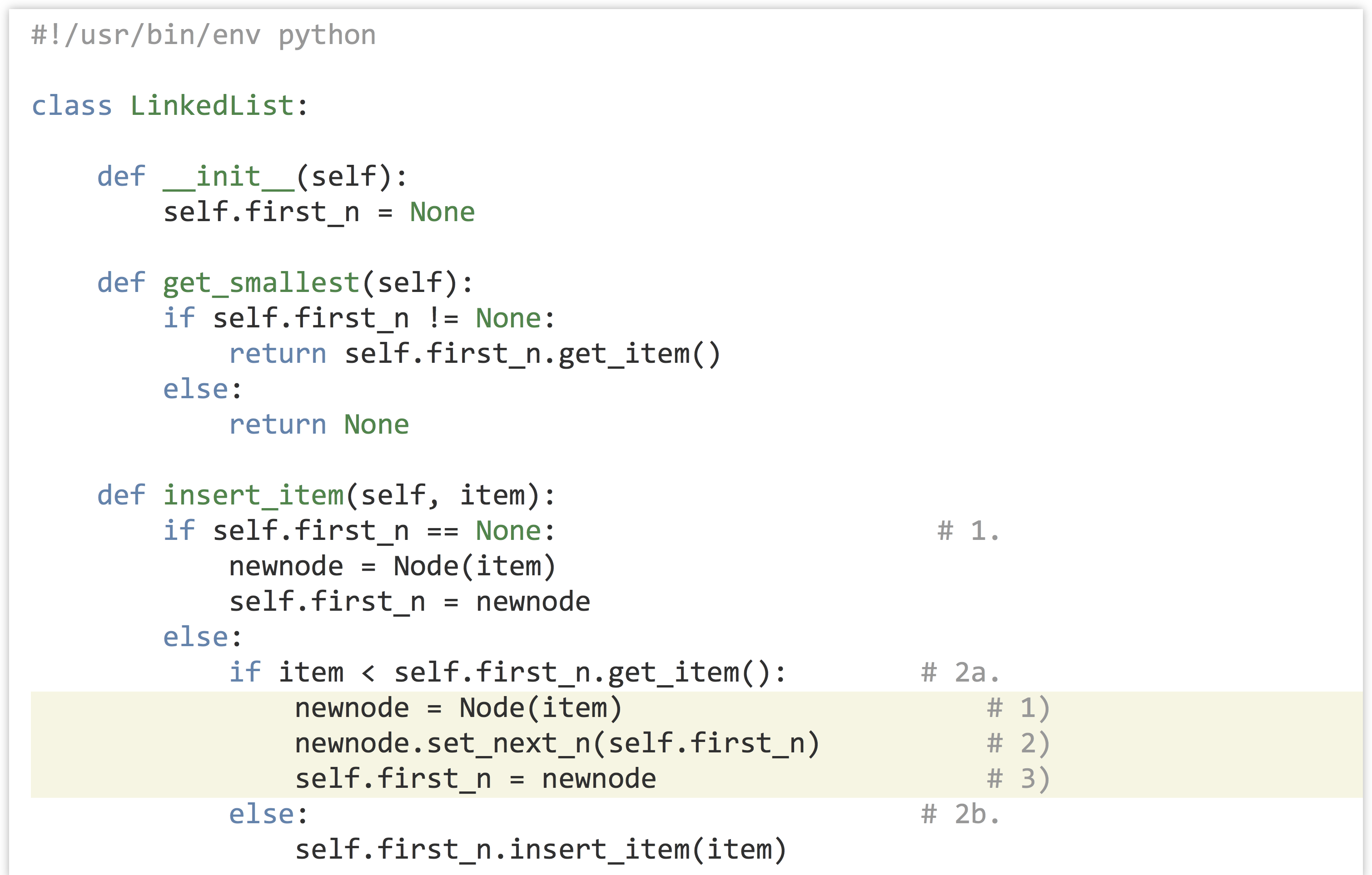
The highlighted lines above are those illustrated in step 2a and are crucial; in particular, the order in which the various variables are set makes all the difference. What would happen if self.first_n = newnode was called before newnode.set_next(self.first_n)? We would lose all references to the rest of the list: itemlist.first_n would refer to newnode, the new node’s .next_n would refer to None, and no variable would refer to the node holding 3—it would be lost in RAM and eventually garbage collected.
As mentioned above, the class for a Node is quite similar. In fact, it is possible to build linked lists with only one object type, but this would necessitate a “dummy” node to represent an empty list anyway (perhaps storing None in its self.item).

Our new data structure is relatively easy to use, and it keeps itself sorted nicely:

Linked List Methods
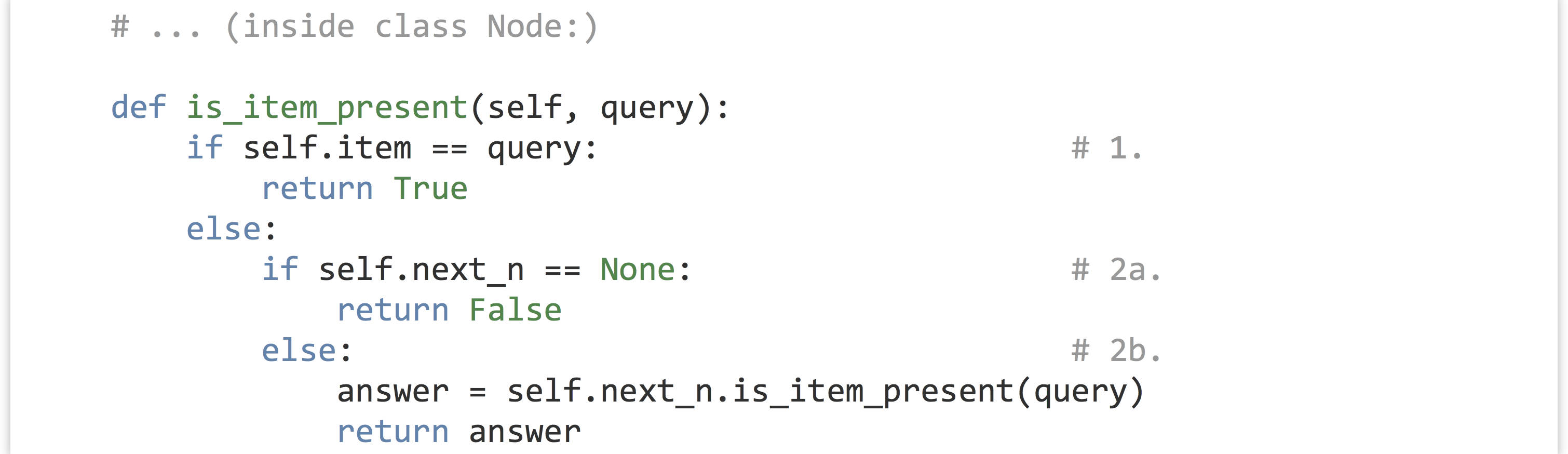
This idea of “passing the buck” between nodes is pretty clever, and it allows us to write sophisticated queries on our data structure with ease. Suppose we wanted to ask whether a given item is already present in the list.
To solve a problem like this, we can think of each node as implementing a decision procedure (using a method, like .is_item_present(query)). The LinkedList interface object would return False if its self.first_n is None (to indicate the list is empty, so the query item can’t be present). If its self.first_n is not None, it calls self.first_n.is_item_present(query), expecting that node to either return True or False.

For a node, the decision procedure is only slightly more complex:
- Check whether
self.itemis equal to thequery. If so, aTruecan safely be returned. - Otherwise:
- If
self.next_nisNone, thenFalsecan be returned, because if the buck got passed to the end of the list, no node has matched thequery. - If
self.next_ndoes exist, on the other hand, just pass the buck down the line, and rely on the answer to come back, which can be returned.
- If
Here is a quick demonstration of the usage (the whole script can be found in the file linkedlist.py):

Notice the similarity in all of these methods: each node first determines whether it can answer the problem—if so, it computes and returns the answer. If not, it checks for a node to pass the problem on to, and if one exists, the buck is passed. Notice that at each buck pass the method being called is the same—it’s just being called for a different object. And each time the overall “problem” gets smaller as the number of nodes left to pass the buck to decreases.
How much time does it take to insert an item into a list that is already of length? Because the new item might have to go at the end of the list, the buck might need to be passed times, meaning an insertion is . What about getting the smallest element? In the LinkedList’s .get_smallest() method, it only needs to determine whether self.first_n is None, and if not, it returns the element stored in that node. Because there is no buck passing, the time is .
| Structure | Insert an Item | Get Smallest |
|---|---|---|
| Sorted Simple List | |
|
| Sorted Linked List | |
|
The creation of the sorted linked list structure didn’t get us much over a more straightforward list kept in sorted order via bubbling, but the ideas implemented here pave the way for much more sophisticated solutions.
Exercises
- How much time would it take to insert sequences into a Python list, and then at the end sort it with bubblesort in the worst-case scenario (using order notation)?
- How much time would it take to insert elements into a sorted linked list that starts empty, in the worst-case scenario (using order notation)? (Note that the first insertion is quick, but the second item might take two buck-passes, the third may take three, and so on.)
- Add “pass the buck” methods to the
LinkedListandNodeclasses that result in each item being printed in order. - Write “pass the buck” methods that cause the list of items to be printed, but in reverse order.
- Add methods to the
LinkedListandNodeclasses so that the linked list can be converted into a normal list (in any order, though reverse order is most natural). For example,print(itemlist.collect_to_list())should print something like['9', '3', '7'].
Divide and Conquer
So far, both the algorithm (bubblesort) and the data structure (sorted linked list) we’ve studied have been linear in nature. Here, we’ll see how these ideas can be extended in “bifurcating” ways.
Let’s consider the sorted linked list from the last section, which was defined by a “controlling” class (the LinkedList) and a number of nearly identical Nodes, each with a reference to a “next” Node object in the line. So long as certain rules were followed (e.g., that the list was kept in sorted order), this allowed each node to make local decisions that resulted in global answers to questions.
What if we gave each node a bit more power? Rather than a single self.next_n instance variable, what if there were two: a self.left_n and a self.right_n? We will need a corresponding rule to keep things organized: smaller items go toward the left, and larger (or equal-sized) items go toward the right. This data structure is the well-known binary tree.
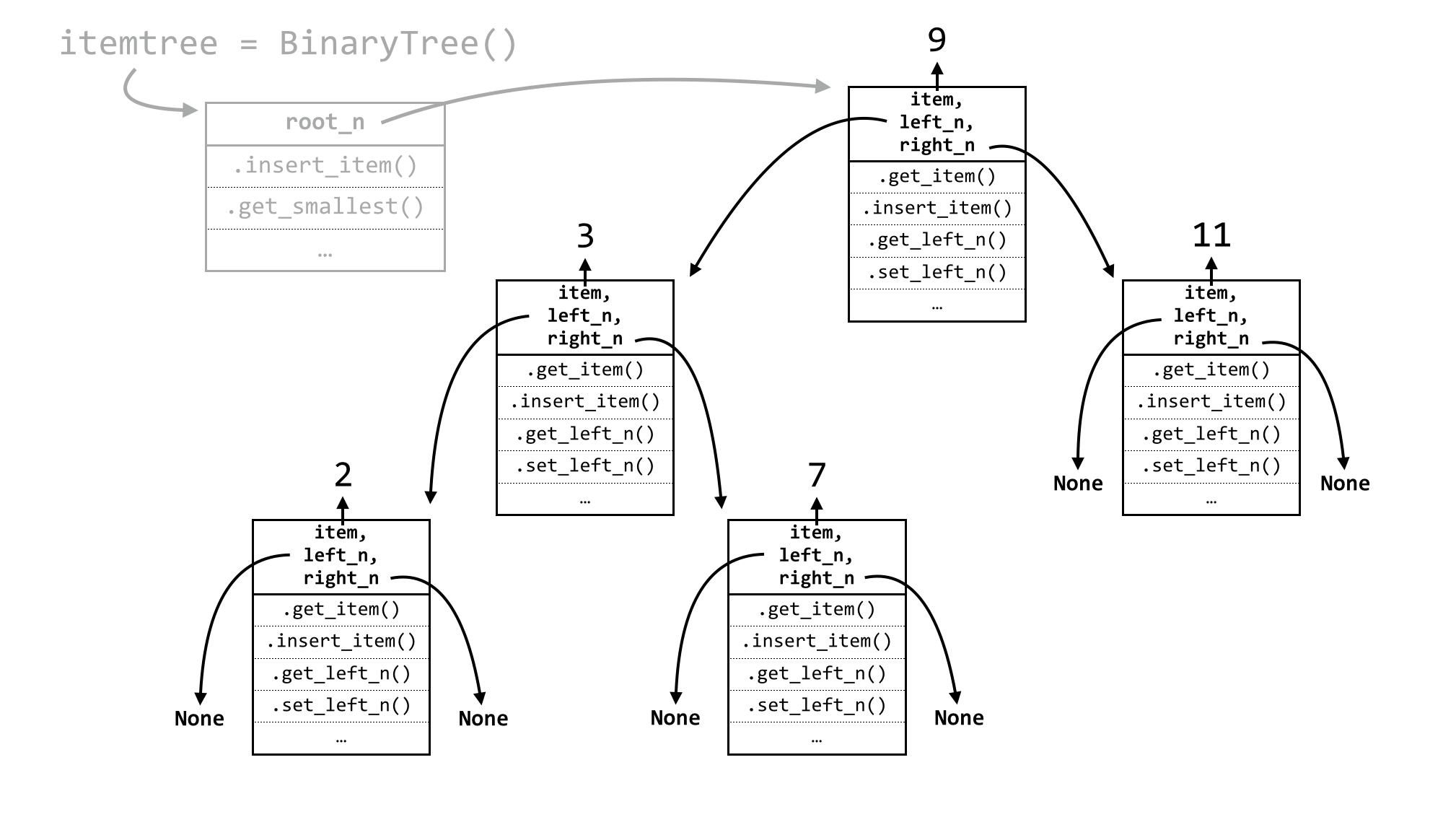
The illustration above looks quite a bit more complicated. But if we inspect this structure closely, it’s quite similar to the linked list:[3] there is a controlling class of BinaryTree, and instead of a self.first_n instance variable, it has an instance variable called self.root_n, because the node it references is the “root” of the tree. Before any items have been inserted, self.root_n will be None. Upon an item insertion, if self.root_n is None, the new item goes there; otherwise, the buck is necessarily passed to self.root_n. We’ll see why in a moment.
Now, for the Node class, we’ll need a constructor, as well as “get” and “set” methods for both left_n and right_n, which initially are set to None.

What about a node’s .insert_item() method? What sort of decision-making process needs to happen? The process is even simpler than for a sorted linked list. If each node always follows the rule that smaller items can be found to the left and larger or equal items can always be found to the right, then new items can always be inserted at the bottom of the tree. In the tree above, for example, a node holding 8 would be placed to the right of (and “below”) the node holding 7. The decision process for a node is thus as follows:
- Is the new item to insert less than our
self.item? If so, the new item goes to the left:- Is
self.left_nequal toNone? If so, then we need to create a new node holding the new item, and setself.left_nto that node. - If not, we can pass the buck to
self.left_n.
- Is
- Otherwise, the item must be larger than or equal to
self.item, so it needs to go to the right:- Is
self.right_nequal toNone? If so, then we need to create a new node holding the new item, and setself.right_nto that node. - If not, we can pass the buck to
self.right_n.
- Is
In the previous figure of a tree, 8 would go to the right of 7, 6 would go to the left of 7, 18 would go the right of 11, and so on. The logic for inserting a new item is thus quite simple, from a node’s point of view:

The remaining method to consider is the tree’s .get_smallest(). In the case of a linked list, the smallest item (if present) was the first node in the list, and so could be accessed with no buck passing. But in the case of a binary tree, this isn’t true: the smallest item can be found all the way to the left. The code for .get_smallest() in the Tree class and the corresponding Node class reflects this.


In the case of a node, if self.left_n is None, then that node’s item must be the smallest one, because it can assume the message was only ever passed toward it to the left. Similar usage code as for the linked list demonstrates that this wonderful structure (binarytree.py) really does work:

The most interesting question is: how much time does it take to insert a new item into a tree that already contains items? The answer depends on the shape of the tree. Suppose that the tree is nice and “bushy,” meaning that all nodes except those at the bottom have nodes to their left and right.

The time taken to insert an item is the number of times the buck needs to be passed to reach the bottom of the tree. In this case, at each node, the total number of nodes in consideration is reduced by half; first, then  , then
, then  , and so on, until there is only a single place the new item could go. How many times can a number be divided in half until reaching a value of 1 (or smaller)? The formula is
, and so on, until there is only a single place the new item could go. How many times can a number be divided in half until reaching a value of 1 (or smaller)? The formula is  . It takes the same amount of time to find the smallest item for a bushy tree, because the length down the left-hand side is the same as any other path to a “leaf” in the tree.
. It takes the same amount of time to find the smallest item for a bushy tree, because the length down the left-hand side is the same as any other path to a “leaf” in the tree.
| Structure | Insert an Item | Get Smallest |
|---|---|---|
| Sorted Simple List | |
|
| Sorted Linked List | |
|
| “Bushy” Binary Tree |  |
|
In general, the logarithm of is much smaller than itself, so a binary tree trades off some speed in finding the smallest element for speed in insertion.
Note, however, that the shape of a tree depends on the order in which the items are inserted; for example if 10 is inserted into an empty tree, followed by 9, the 9 will go to the left. Further inserting 8 will put it all the way to the left of 9. Thus, it is possible that a tree isn’t in fact bushy, but rather very unbalanced. For an extreme example, if the numbers from  were inserted in that order, the tree would look like so:
were inserted in that order, the tree would look like so:
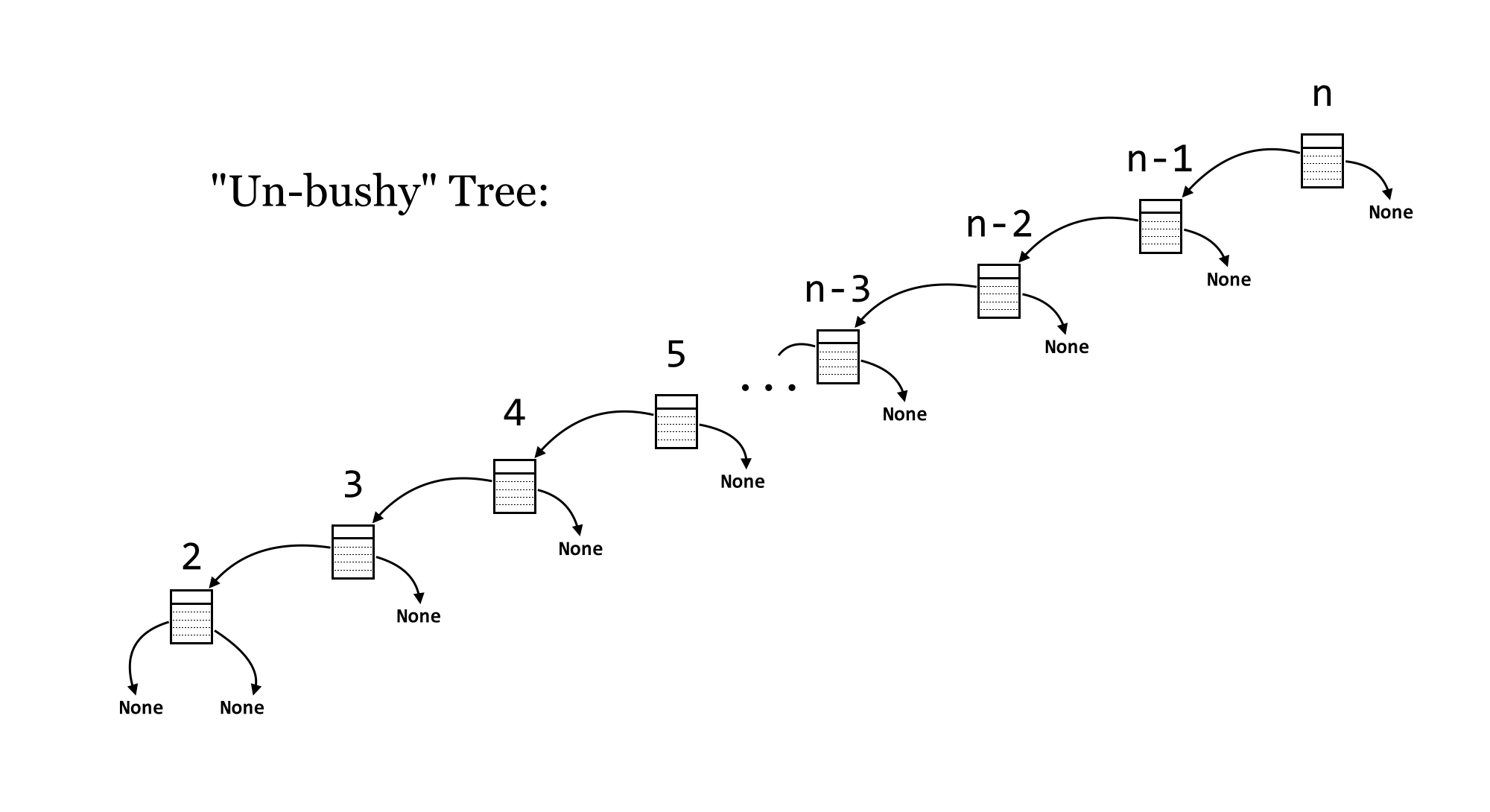
In this case, the tree has degenerated into a reverse-sorted linked list. So, the insertion time (for 1, for example) is , and finding the smallest item is also, because the tree is heavily unbalanced in a leftward direction. Unfortunately, in practice, we can’t guarantee the order in which data will be inserted, and such runs of consecutive insertions aren’t uncommon in real-world data.
More sophisticated structures called “balanced” binary trees have modifications to their insertion methods that ensure the tree stays bushy, no matter what order items are inserted. This is tricky, as it requires manipulating the structure of the tree after insertions, but the structure manipulation itself can’t take too long or the benefit of insertion is lost. Examples of balanced binary trees include so-called red-black trees, and AVL trees (named after Georgy Adelson-Velsky and Evgenii Landis, who first described them).
| Structure | Insert an Item | Get Smallest |
|---|---|---|
| Sorted Simple List | |
|
| Sorted Linked List | |
|
| “Bushy” Binary Tree | |
|
| “Un-bushy” Binary Tree | |
|
| Balanced Binary Tree | |
|
In practice, we don’t make a distinction between “bushy” and “un-bushy” binary trees: simple binary-search trees are for both .insert_item() and .get_smallest(), because we cannot guarantee bushiness (recall that we assume worst-case performance when analyzing an algorithm). Real applications thus use AVL trees, red-black trees, or other more sophisticated data structures.
Exercises
- Add “pass the buck” methods to
BinaryTreeand itsNodeclass for.print_in_order()and.print_reverse_order(), causing the items to be printed in sorted and reverse-sorted order, respectively. - Add
.count_nodes()methods that return the total number of items stored in the tree. How long does it take, in order notation? Does this depend on whether the tree is bushy or not? If so, what would be the run time for a bushy versus un-bushy tree? - Add
.count_leaves()methods that return the total number of “leaves” (nodes withNoneinleft_nandright_n). - Binary search trees are so called because they can easily and efficiently determine whether a query item is present. Add
.is_item_present()methods that returnTrueif a query item exists in the tree andFalseotherwise (similar to theLinkedList.is_item_present()). How long does it take, in order notation? Does this depend on whether the tree is bushy or not? If so, what would be the run time for a bushy versus un-bushy tree? - Modify the binary tree code so that duplicate items can’t be stored in separate nodes.
Back to Sorting
We previously left the topic of sorting having developed bubblesort, an method for sorting a simple list of items. We can certainly do better.
One of the interesting features of the insert_item() method used by nodes in both the tree and linked list is that this method, for any given node, calls itself, but in another node. In reality, there aren’t multiple copies of the method stored in RAM; rather, a single method is shared between them, and only the self parameter is really changing. So, this method (which is just a function associated with a class) is actually calling itself.
In a related way, it turns out that any function (not associated with an object) can call itself. Suppose we wanted to compute the factorial function, defined as
![\[factorial(n) = n\times(n-1)\times(n-2)\times\dots\times2\times1\ .\]](https://open.oregonstate.education/app/uploads/quicklatex/quicklatex.com-fb144cc4c49b25a5673c6daf58200ba4_l3.png "Rendered by QuickLaTeX.com")
One of the most interesting features of the factorial function is that it can be defined in terms of itself:
![\[ factorial(n) = \begin{cases} 1, \\ n \times factorial(n-1), \end{cases} \begin{aligned} &\text{if } n = 1, \\ &\text{otherwise.} \end{aligned} \]](https://open.oregonstate.education/app/uploads/quicklatex/quicklatex.com-0255b9d69af7d84bcfdb73939c10a9a6_l3.png "Rendered by QuickLaTeX.com")
If we wanted to compute factorial(7), a logical way to think would be: “first, I’ll compute the factorial of 6, then multiply it by 7.” This reduces the problem to computing factorial(6), which we can logically solve in the same way. Eventually we’ll want to compute factorial(1), and realize that is just 1. The code follows this logic impeccably:

As surprising as it might be, this bit of code really works.[4] The reason is that the parameter n is a local variable, and so in each call of the function it is independent of any other n variable that might exist.[5] The call to factorial(7) has an n equal to 7, which calls factorial(6), which in turn gets its own n equal to 6, and so on. Each call waits at the subanswer = factorial(n-1) line, and only when factorial(1) is reached do the returns start percolating back up the chain of calls. Because calling a function is a quick operation (), the time taken to compute factorial(n) is , one for each call and addition computed at each level.

This strategy—a function that calls itself—is called recursion. There are usually at least two cases considered by a recursive function: (1) the base case, which returns an immediate answer if the data are simple enough, and (2) the recursive case, which computes one or more subanswers and modifies them to return the final answer. In the recursive case, the data on which to operate must get “closer” to the base case. If they do not, then the chain of calls will never finish.
Applying recursion to sorting items is relatively straightforward. The more difficult part will be determining how fast it runs for a list of size. We’ll illustrate the general strategy with an algorithm called quicksort, first described in 1960 by Tony Hoare.
For an overall strategy, we’ll implement the recursive sort in a function called quicksort(). The first thing to check is whether the list is of length 1 or 0: if so, we can simply return it since it is already sorted. (This is the base case of the recursive method.) If not, we’ll pick a “pivot” element from the input list; usually, this will be a random element, but we’ll use the first element as the pivot to start with. Next, we’ll break the input list into three lists: lt, containing the elements less than the pivot; eq, containing the elements equal to the pivot; and gt, containing elements greater than the pivot. Next, we’ll sort lt and gt to produce lt_sorted and gt_sorted. The answer, then, is a new list containing first the elements from lt_sorted, then the elements from eq, and finally the elements from gt_sorted.
The interesting parts of the code below are the highlighted lines: how do we sort lt and gt to produce lt_sorted and gt_sorted?
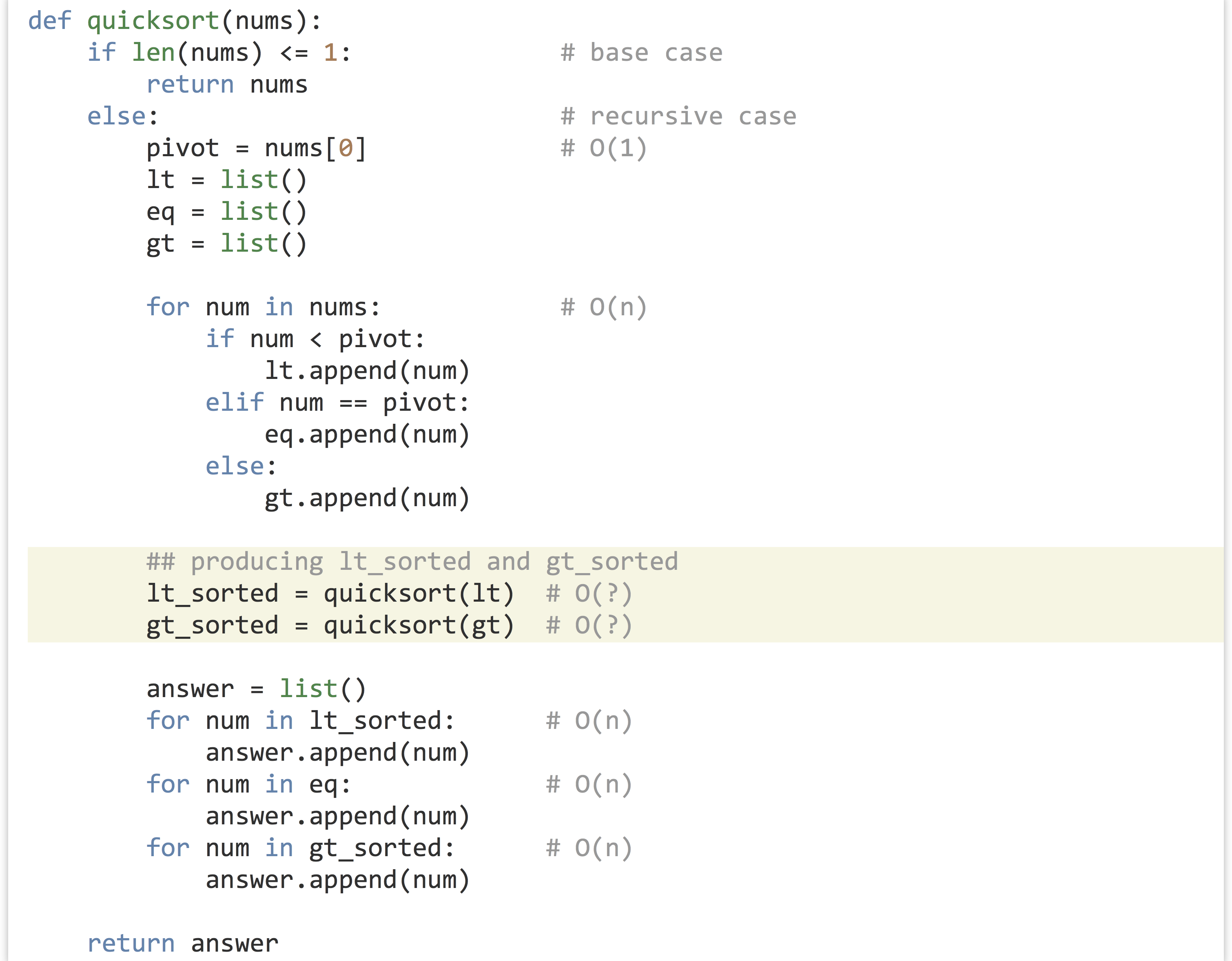
We could use Python’s built-in sorted() function, but that’s clearly cheating. We could use bubblesort, but doing so would result in our function suffering the same time bound as for bubblesort (we say “time bound” because the order notation essentially provides an upper bound on time usage). The answer is to use recursion: because lt and gt must both be smaller than the input list, as subproblems they are getting closer to the base case, and we can call quicksort() on them!

Let’s attempt to analyze the running time of quicksort()—will it be better than, equal to, or worse than bubblesort? As with the binary trees covered previously, it turns out the answer is “it depends.”
First, we’ll consider how long the function takes to run—not counting the subcalls to quicksort()—on a list of size. The first step is to pick a pivot, which is quick. Next, we split the input list into three sublists. Because appending to a list is quick, but all elements need to be appended to one of the three, the time spent in this section is . After the subcalls, the sorted versions of the lists need to be appended to the answer list, and because there are things to append, the time there is also . Thus, not counting the recursive subcalls, the run time is plus which is .
But that’s not the end of the story—we can’t just ignore the time taken to sort the sublists, even though they are smaller. For the sake of argument, let’s suppose we always get “lucky,” and the pivot happens to be the median element of the input list, so len(lt) and len(gt) are both approximately . We can visualize the execution of the function calls as a sort of “call tree,” where the size of the nodes represents how big the input list is.
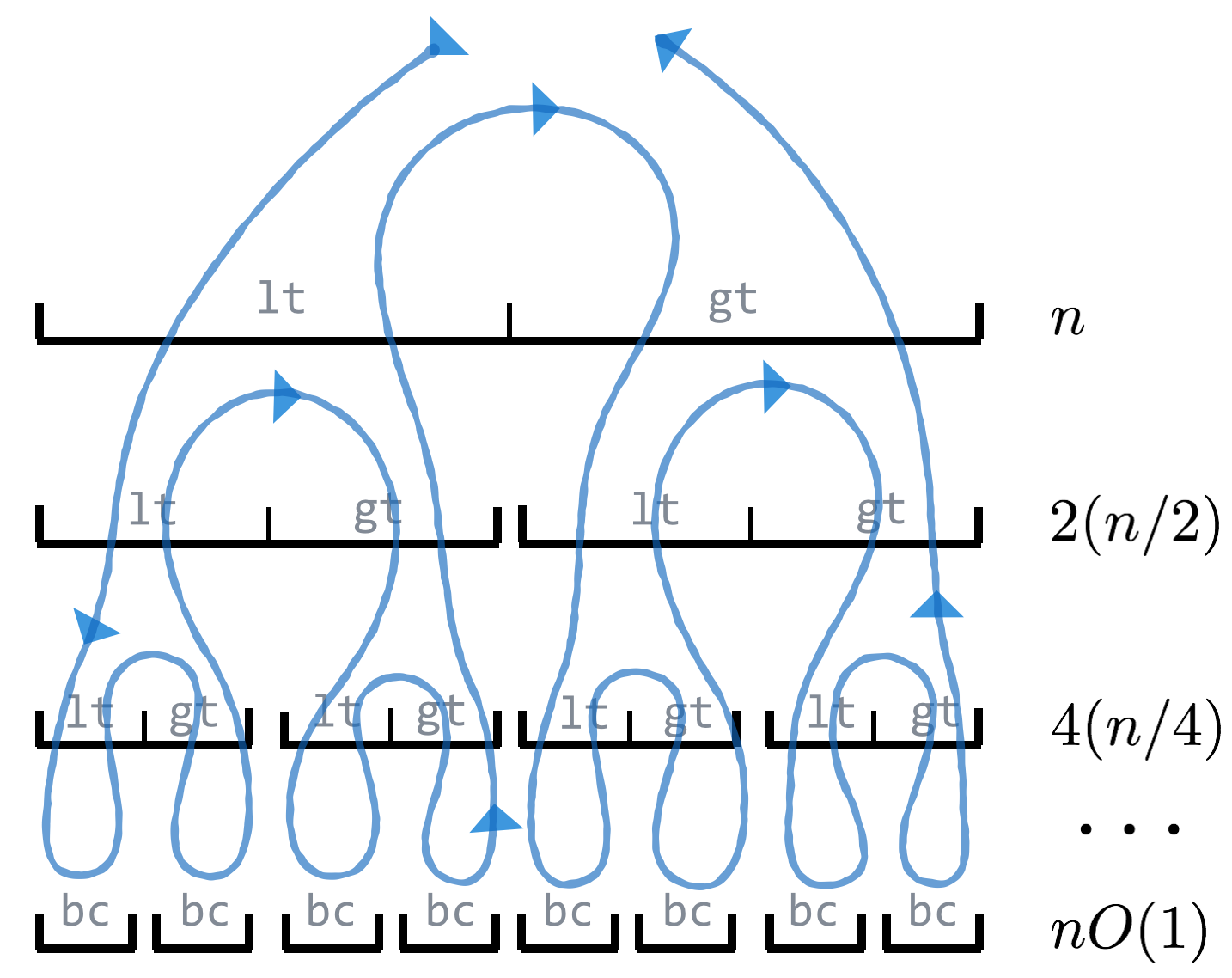
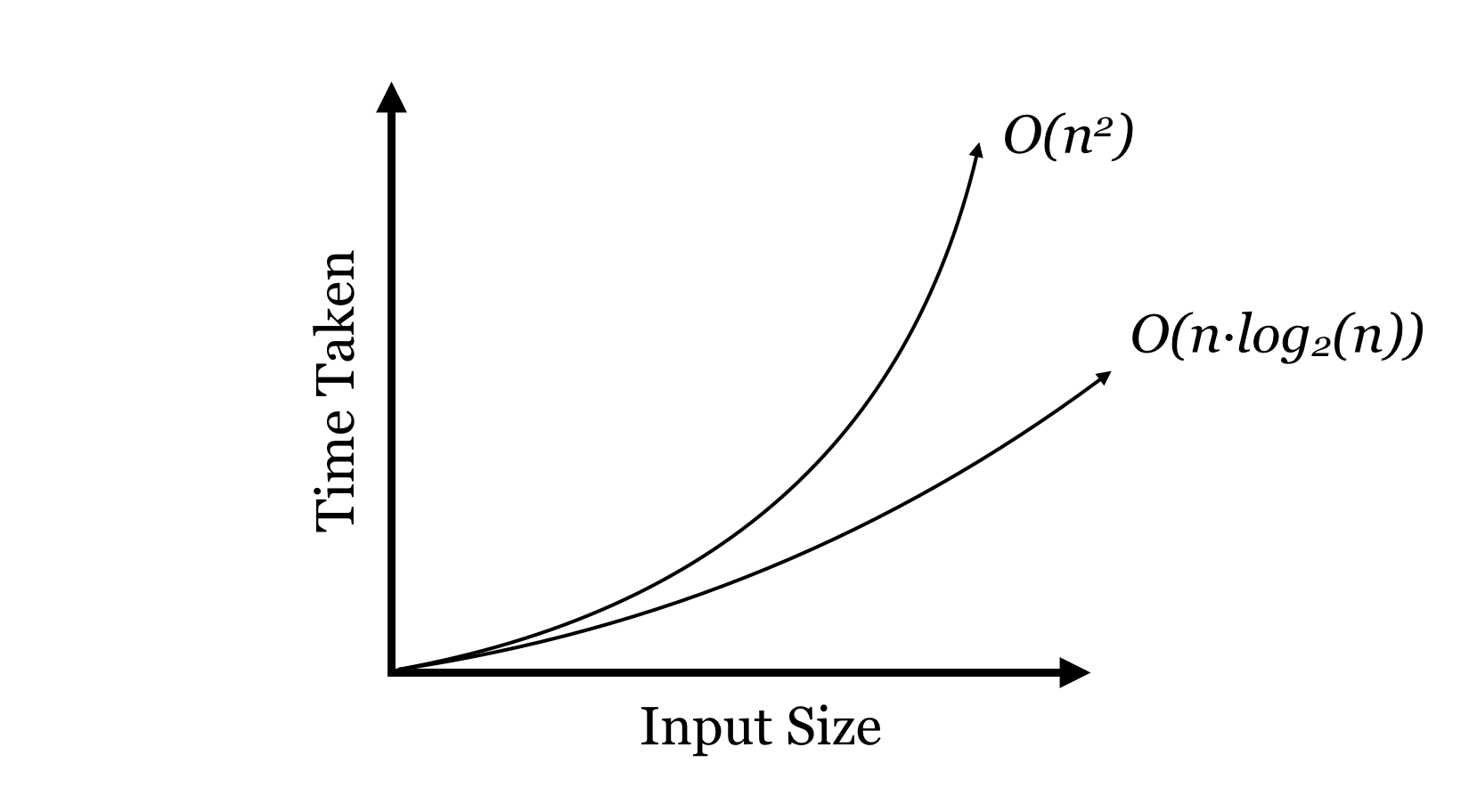
Here, the top “node” represents the work done by the first call; before it can finish, it must call to sort the lt list on the second layer, which must again call to sort its own lt list, and so on, until the bottom layer, where a base case is reached. The path of execution can be traced in the figure along the line. To analyze the run time of the algorithm, we can note that the amount of work done at each layer is , so the total amount of work is this value times the number of layers. In the case where the pivots split the lists roughly in half, the result is the same as the number of layers in the bushy binary tree: . Thus, in this idealized scenario, the total run time is  , which is much better than the of bubblesort.[6]
, which is much better than the of bubblesort.[6]
This equation assumes that the pivots split the input lists more or less in half, which is likely to be the case (on average), if we choose the pivots at random. But we didn’t choose at random; we used nums[0]. What would happen if the input to the list happened to be already sorted? In this case, the pivot would always be the first element, lt would always be empty, and gt would have one fewer element. The “work tree” would also be different.

In this “unlucky” case, the work on each level is approximately  , and so on, so the total work is
, and so on, so the total work is 



 which is . Does this mean that in the worst case
which is . Does this mean that in the worst case quicksort() is as slow as bubblesort? Unfortunately, yes. But some very smart people have analyzed quicksort() (assuming the pivot element is chosen at random, rather than using the first element) and proved that in the average case the run time is , and the chances of significantly worse performance are astronomically small. Further, a similar method known as “mergesort” operates by guaranteeing an even 50/50 split (of a different kind).
| Algorithm | Average Case | Worst Case |
|---|---|---|
| Bubblesort | |
|
| Quicksort | |
|
| Mergesort | |
|
Using random selection for pivot, quicksort() is fast in practice, though mergesort and similar algorithms are frequently used as well. (Python’s .sort() and sorted() use a variant of mergesort called “Timsort.”) Although as mentioned above worst-case analysis is most prevalent in algorithms analysis, quicksort() is one of the few exceptions to this rule.
These discussions of algorithms and data structures might seem esoteric, but they should illustrate the beauty and creativeness possible in programming. Further, recursively defined methods and sophisticated data structures underlie many methods in bioinformatics, including pairwise sequence alignment, reference-guided alignment, and Hidden Markov Models.
Exercises
- The first step for writing
mergesort()is to write a function calledmerge(); it should take two sorted lists (together comprising elements) and return a merged sorted version. For example, merge([1, 2, 4, 5, 8, 9, 10, 15], [2, 3, 6, 11, 12, 13])should return the list[1, 2, 2, 3, 4, 5, 6, 8, 9, 10, 11, 12, 13, 15], and it should do so in time, where is the total number of elements from both lists. (Note that .append()on a Python list is time, as are mathematical expressions like c = a + b, but other list operations like.insert()are not.)The
mergesort()function should first split the input list into two almost-equal-sized pieces (e.g.,first_half = input_list[0:len(input_list)/2]); these can then be sorted recursively withmergesort(), and finally themerge()function can be used to combine the sorted pieces into a single answer. If all steps in the function (not counting the recursive calls) are, then the total time will be .Implement
merge()andmergesort(). - The Fibonacci numbers (1, 1, 2, 3, 5, 8, 13, etc.) are, like the factorials, recursively defined:
![\[ \text{Fib}(n) = \begin{cases} 1 \\ 1 \\ \text{Fib} (n - 1) + \text{Fib} (n - 2) \end{cases} \begin{aligned} &\text{if } n = 1, \\ &\text{if } n = 2,\\ &\text{otherwise.} \end{aligned} \]](https://open.oregonstate.education/app/uploads/quicklatex/quicklatex.com-8101524baa3ac30132c01cac26eb643b_l3.png "Rendered by QuickLaTeX.com")
Write a recursive function
fib()that returns theth Fibonacci number (fib(1)should return1,fib(3)should return2,fib(10)should return55). - Next, write a function called
fib_loop()that returns theth Fibonacci by using a simple loop. What is the run time, in order notation, in terms of? Compare how long it takes to compute fib(35)versusfib_loop(35), and then tryfib(40)versusfib_loop(40). Why do you thinkfib()takes so much longer? Try drawing the “call trees” forfib(1),fib(2),fib(3),fib(4),fib(5), andfib(6). Could you make a guess as to what the run time of this function is in order notation? Can you imagine any ways it could be sped up?
- When analyzing an algorithm in Python, however, not all lines are a single computational step. For example, Python has a built-in
sorted()function for sorting, and although it is not as slow as bubblesort, it takes much longer than one step to sort millions of numbers. If an algorithm makes use of a function likesorted(), the run time of that (based on the size of the input given) also needs to be considered. A function that calls our bubblesort function times, for example, would run in time . ↵ - There is no reason a
Nodeobject couldn’t also hold other information. For example, nodes could have aself.snpto hold anSNPobject as well, withself.itembeing the location of the SNP, so SNPs are stored in order of their locations. ↵ - If we ignore all the nodes’
self.left_nreferences (i.e., the entire left side of the tree), then theself.right_npath from top to the lower right is a sorted linked list! Similarly, the path from the top to the lower left is a reverse-sorted linked list. ↵ - Factorials can be easily (and slightly more efficiently) computed with a loop, but we’re more interested in illustrating the concept of a self-calling function. ↵
- Additionally, the operations of defining a function and executing it are disjoint, so there’s nothing to stop a function being defined in terms of itself. ↵
- This proof is a visually oriented one, and not terribly rigorous. A more formalized proof would develop what is known as a recurrence relation for the behavior of the algorithm, in the form of
 , to be solved for
, to be solved for  , representing the time taken to sort items. ↵
, representing the time taken to sort items. ↵
