3 TE 1.0 – XML
Introduction
TE 1.0 relied heavily on Extensible Markup Language (XML). XML was invented in the second half of the 1990s to overcome a fundamental problem of the early world-wide web. The problem was that the predominant language for representing web content, HyperText Markup Language (HTML), was meant to express how information was to be formatted on web pages to be viewed by human users, but that that formatting was of little use to ‘users’ represented by machines; i.e., programs. Whereas humans are quite good at extracting meaning from how information is formatted, programs just need content, and formatting only gets in the way of extracting that content. Yet HTML was meant to specify content through formatting. XML solved this problem by providing a text-based and structured way to specify content without formatting.
In this chapter, we introduce XML as a data representation and data exchange format and provide some examples of how it was used in TE 1.0. In the next chapter, we discuss XML’s recent competitor and TE 2.0’s choice: JSON. In the chapter following the JSON chapter we go deeper into how XML was used in TE 1.0 and how JSON is used in TE 2.0.
Representing Content With XML
One of the more influential advances in modern-day electronic data exchange, and one which caused web-based data exchanges to flourish, was the introduction and standardization of Extensible Markup Language (XML) in the late 1990s (Bosak & Bray, 1999). Until that time, messages requested and served over the web were dominated by the HyperText Markup Language (HTML). As explained in the 1999 article in Scientific American by Jon Bosak and Tim Bray ―two of the originators of the XML specification― HTML is a language for specifying how documents must be formatted and rendered, typically so that humans can easily read them. However, HTML is not very well suited for communicating the actual content of documents (in terms of their information content) or for that matter, any set of data. This deceptively simple statement requires some explanation.
When we, as humans, inspect web pages, we use their formatting and layout to guide us through their organization and contents. We look at a page and we may see sections and paragraphs, lists and sublists, tables, figures, and text, all of which help us to order, structure, and understand the contents of the document. In addition, we read the symbols, words, figure captions, and sentences, gleaning their semantic contents from the terms and expressions they contain. As a consequence, on a web page we can immediately recognize the stock quote or the trajectory of the share price over the last six hours from a chart, a table or even a text. Since a human designed the page to be read and processed by another human, we can count on each other’s perceptual pattern recognition and semantic capabilities when exchanging information through a formatted text. We are made painfully aware of this when confronted with a badly structured, cluttered or poorly formatted HTML web page or when the page was created by someone with a different frame of mind or a different sense of layout or aesthetics. What were the authors thinking when they put this page together?
However, if we want to offer contents across the web that must be consumed by programs rather than human beings, we can no longer rely on the formats, typesetting and even the terms of the document to implicitly communicate meaning. Instead, we must provide an explicit semantic model of the content of the document along with the document itself. It is this ability to provide content along with a semantic model of that content that makes XML such a nice language for programmatic data exchange.
Although for details on XML, its history, use and governance, we refer to the available literature on this topic; we provide here a small example of this dual provision of contents and semantics.
Consider TeachEngineering: an electronic collection of lesson materials for K-12 STEM education. Now suppose that we want to give others; i.e., machines other than our own, access to those materials so that those machines can extract information from them. What should these lesson materials look like when requested by such an external machine or program? Let us simplify matters a little and assume that a TE lesson consists of only the following:
- Declaration that says it is a lesson
- Lesson title
- Target grade band
- Target lesson duration
- Needed supplies and their estimated cost
- Summary
- Keywords
- Educational standards to which the lesson is aligned
- Main lesson contents
- References (if applicable)
- Copyright
In XML such a lesson might be represented as follows:
<lesson>
<title>Hindsight is 20/20</title>
<grade target="5" lowerbound="3" upperbound="6"/>
<time total="50" unit="minutes"/>
<lesson_cost amount="0" unit="USDollars"/>
<summary>Students measure their eyesight and learn how lenses can
enhance eyesight.
</summary>
<keywords>
<keyword>eyesight</keyword>
<keyword>vision</keyword>
<keyword>20/20</keyword>
</keywords>
<edu_standards>
<edu_standard identifier="14000"/>
<edu_standard identifier="14011"/>
</edu_standards>
<lesson_body>With our eyes we see the world around us. Having two
eyes helps us see a larger area than just one eye and with two
eyes we can... etc. etc.
</lesson_body>
<copyright owner="We, the legal owners of this document"
year="2016"/>
</lesson>
Notice how the various components of a lesson are each contained in special tags such as <copyright> or <title>. Hence, to find which educational standards this lesson supports, all we have to do is find the <edu_standards> tag and each of the <edu_standard> tags nested within it.
![]()
Exercise 3.1
Copy the above XML fragment to a file called something.xml and pick it up with your web browser (Control-O makes your web browser pop up a file browser). Notice that your web browser recognizes the content of the file as XML and renders it accordingly. Note how the indentation of the various lines matches the nesting of the data. For instance, your browser indents <keyword>s because they are contained within the <keywords> tag. The same applies to the <edu_standards> and <edu_standard> tags.
The above XML format is rather rigid and not entirely pleasant for us humans to read. However, it is this rigid notion of information items placed inside these tags and tags themselves placed within other tags that provides three essential advantages for machine-based reading:
- Information is represented in a hierarchical format; i.e., tags inside other tags. Hierarchies provide a lot of expressiveness; i.e., most (although not all) types of information can be expressed by means of a hierarchy.
- It is relatively easy to write programs that can read and process hierarchically organized data.
- If such a program cannot successfully read such a data set, it is likely that the data set is not well formed and hence, we have a good means of distinguishing well-formed from malformed data sets.
Let us take a look at another example. Figure 1 contains the music notation of a fragment from Beethoven’s famous fifth symphony (listen to it!):

For those who can read music notation, the information contained in this image is clear:
- The piece is set in the key of C-minor (
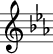 ) (or E-flat major: from these first few bars you cannot really tell which of the two it is). This implies that E’s, B’s and A’s must be flattened (
) (or E-flat major: from these first few bars you cannot really tell which of the two it is). This implies that E’s, B’s and A’s must be flattened ( ).
). - Time signature is 2/4; i.e., two quarter-note beats per bar (
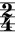 ).
). - First bar consists of a ½-beat rest (
 ) followed by three ½-beat G’s (
) followed by three ½-beat G’s ( ).
). - Second bar contains a 2-beat E-flat (
 ). The note has a fermata (
). The note has a fermata (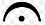 ), indicating that the performer or conductor is free to hold the note as long as desired.
), indicating that the performer or conductor is free to hold the note as long as desired. - The two 2-beat D’s in bars four and five must be connected (tied or ‘slurred’) and played as a single 4-beat note. Once again, this note has a fermata and can therefore be held for as long as desired (
 ).
).
Fot those who can read music, all this information is stored in the graphic patterns of music notation. For instance, it is the location of a note relative to the five lines in the staff and the staff’s clef (![]() ) which indicates its pitch, and the duration of a note is indicated by whether it is solid or open or how notes are graphically connected. Likewise, the fermata is just a graphical symbol which we interpret as an instruction on how long to hold the note.
) which indicates its pitch, and the duration of a note is indicated by whether it is solid or open or how notes are graphically connected. Likewise, the fermata is just a graphical symbol which we interpret as an instruction on how long to hold the note.
However, whereas this kind of information is relatively easy for us humans to glean from the graphic patterns, for a machine, this is not nearly so easy. Although in these days of optical pattern recognition and machine learning we are quickly getting closer to this, a much more practical approach would be to write this same information in unformatted text such as XML so that a program can read it and do something with it.
What might Beethoven’s first bars of Figure 1 look like in XML? How about something like the following?[1]
<score>
<clef>g</clef>
<key base_note=”c” qualifier=”minor”>
<key_modifiers>
<note>E</note><mod>flat</mod>
<note>B</note><mod>flat</mod>
<note>A</note><mod>flat</mod>
</key_modifiers
</key>
<time_signature numerator = “2” denominator=”4”/>
<bars>
<bar count=”1”>
<rest bar_count = “1” duration=”8”/>
<note bar_count = “2” pitch=”G” duration=”8”/>
<note bar_count = “3” pitch=”G” duration=”8”/>
<note bar_count = “4” pitch=”G” duration=”8”/>
</bar>
<bar count=”2”>
<note bar_count = “1” pitch=”E” duration=”2”
articulation=”fermata”/>
</bar>
.
.
.
Etc.
</bars>
</score>
Looking at the example above, you may wonder about why some information is coded as so-called XML elements (entries of the form <tag>information</tag>), whereas other information is coded in the form of so-called attributes (entries in the form of attribute=”value”). For instance, instead of
<note bar_count = “4” pitch=”G” duration=”8”/>
could we not just as well have written the following?
<note> <bar_count>4</bar_count> <pitch>G</pitch> <duration>8</duration> </note>
The answer is that either way of writing this information works just fine. As far as we know, a choice of one or the other is essentially a matter of convenience and aesthetics on the side of the designer of the XML specification. As we mention in the next chapter (JSON; an Alternative for XML), however, this ambivalence is one of the arguments that JSON aficionados routinely use against XML.
At this point you should not be surprised that indeed there are several XML models for representing music. One of them is MusicXML.[2]
This notion of communicating information with hierarchically organized text instead of graphics naturally applies to other domains as well. Take, for instance mathematical notation. Figure 2 shows the formula for the (uncorrected) standard deviation.
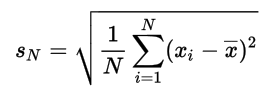
Once again, we humans can read this information just fine because we have a great capacity (and training) to glean its meaning from its symbols and their relative positions. But as was the case with the music graphic, asking a machine to decipher these same symbols and relative positions seems like the long way around. Why not just represent the same information in hierarchic textual, XML form? Something like the following:
<equation>
<left_side>
<term>
<symbol>S</symbol>
<sub><var>N</var></sub>
</term>
</left_side>
<right_side>
<sqrt>
<product>
<left>
<quotient>
<nominator>1</nominator>
<denominator><var>N</var></denominator>
</quotient>
</left>
<right>
<sum>
Etc.
</sum>
</right>
</product>
</sqrt>
</right_side>
</equation>
As with the music example, this XML was entirely made up by us and is only meant to illustrate the notion of representing content in hierarchical text form which is normally represented in graphic form. However, MathML is a standard implementation of this.
What is interesting in MathML is that it consists of two parts: Presentation MathML and Content MathML. Whereas Presentation MathML is comparable with standard HTML, i.e., a language for specifying how mathematical expressions must be displayed, Content MathML corresponds to what we tried to show above, namely a textual presentation of the structure and meaning of mathematical expressions. The following sample is taken verbatim from the MathML Wikipedia page:
Expression: ax2 + bx + c
MathML:
<math>
<apply>
<plus/>
<apply>
<times/>
<ci>a</ci>
<apply>
<power/>
<ci>x</ci>
<cn>2</cn>
</apply>
</apply>
<apply>
<times/>
<ci>b</ci>
<ci>x</ci>
</apply>
<ci>c</ci>
</apply>
</math>
Lots of XML specifications other than MusicML and MathML have been developed over the years. One which is currently in active use by the US Securities and Exchange Commission (SEC) is XBRL for business reporting (Baldwin & Brown, 2006). For a list of many more, point your web browser to https://en.wikipedia.org/wiki/List_of_XML_markup_languages.
XML Syntax Specification: DTD and XML Schema
One of the characteristics of programs which serve XML content over the web, is that they can be self-describing using a so-called Document Type Definition (DTD) or the more recent XML Schema Definition (XSD). DTS and XSD are meta documents, meaning that they contain information about the documents containing the actual XML data. This meta information serves two purposes: it informs programmers (as well as programs) on how to interpret an XML document and it can be used to check an XML document against the rules specified for that XML (a process known as ‘validation’).
A helpful way to understand this notion is to consider a DTD/XSD document to specify the syntax ―grammar and vocabulary― of an XML specification. For instance, going back to the example of our TeachEngineering 1.0 lesson, the DTD/XSD for the lesson would specify that a lesson document must have a title, a target grade band, one or more keywords, one or more standard alignments, time and cost estimates, etc. It would further specify that a grade band contains a target grade and a low and a high grade which are numbers, that the keyword list contains at least one keyword which itself is a string of characters, that a copyright consists of an owner and a year, etc.
A fragment of the XSD for the above lesson document defining the syntax for the grade, time and keyword information might look something like the following (Note: line numbers are included here for reference only; they would not be part of the schema document):
1 <?xml version="1.0" encoding="UTF-8"?> 2 <xs:schema xmlns:xs="http://www.w3c.org/2001/XMLSchema"> 3 <xs:element name="lesson"> 4 <xs:complexType> 5 <xs:sequence> 6 7 <!--semantics for the <grade> element--> 8 <xs:element name="grade"> 9 <xs:complexType> 10 <xs:simpleContent> 11 <xs:extension base="xs:unsignedByte"> 12 <xs:attribute name="lowerBound" type="xs:unsignedByte" 13 use="optional"/> 14 <xs:attribute name="upperBound" type="xs:unsignedByte" 15 use="optional"/> 16 </xs:extension> 17 </xs:simpleContent> 18 </xs:complexType> 19 </xs:element> 20 21 <!--semantics for the <time> element--> 22 <xs:element name=”time”> 23 <xs:complexType> 24 <xs:simpleContent> 25 <xs:extension base="xs:float"> 26 <xs:attribute name="unit" use="required"> 27 <xs:simpleType> 28 <xs:restriction base="xs:string"> 29 <xs:enumeration value="minutes"/> 30 <xs:enumeration value="hours"/> 31 <xs:enumeration value="days"/> 32 <xs:enumeration value="weeks"/> 33 </xs:restriction> 34 </xs:simpleType> 35 </xs:attribute> 36 </xs:extension> 37 </xs:simpleContent> 38 </xs:complexType> 39 </xs:element> 40 41 <!--semantics for the <keywords> element--> 42 <xs:element name="keywords"> 43 <xs:complexType> 44 <xs:sequence> 45 <xs:element name="keyword" type="string" maxOccurs="unbounded"/> 46 </xs:sequence> 47 </xs:complexType> 48 </xs:element> 49 Etc.
Notice how the schema specifies how components of an XML lesson must be structured. For instance, the <keywords> element (line 42-48) is defined as a sequence of <keyword>s where each <keyword> is a string of characters of any length (line 45). Similarly, the lesson <time> (line 22-39) has a value which is a floating-point number and has a required <unit> which is one of the strings’ minutes, hours, days or weeks (line 28-33).
As for the xs: prefix on all definitions, the code
xmlns:xs="http://www.w3c.org/2001/XMLSchema"
on line 2 indicates that each of these terms ―element, complexType, sequence, string, etc.― is defined by the W3C’s 2001 XMLSchema.
Note: Well formed ≠ Valid
Now we have discussed both XML and DTD/XSD, we can make the distinction between well-formed and malformed XML documents on the one hand and valid and invalid ones on the other (Table 1).
| – | Well formed | Malformed |
|---|---|---|
| Valid | 1 | |
| Invalid | 2 | 3 |
An XML document is considered well formed if it obeys the basic XML syntax rules. With this, we mean that all content is stored within XML elements; i.e., that all content is tag delimited and properly nested. A simple example/exercise clarifies this.
![]()
Exercise 3.2
Store the following text in a file with .xml extension and pick it up with your web browser (Control-o makes the web browser pop up a file browser):
<art_collection>
<object type="painting"
<title>Memory of the Garden at Etten</title>
<artist>Vincent van Gogh</artist>
<year>1888</year>
<description>Two women on the left. A third works in her
garden</description>
<location>
<place>Hermitage</place>
<city>St. Petersburg</city>
<country>Russia</country>
</location>
</object
<object type="painting">
<title>The Swing</title>
<artist>Pierre Auguste Renoir</artist>
<year>1886</year>
<description>Woman on a swing. Two men and a toddler
watch</description>
<location>
<place>Musee d'Orsay</place>
<city>Paris</city>
<country>France</country>
</location>
</object>
</art_collection>
Notice how your web browser complains about a problem on line 3 at position 9. It sees the <title> element, but the previous element <object> has no closing chevron (>) and hence, the <title> tag is in an illegitimate position. Regardless of any of the values and data stored in any of the elements, this type of error violates the basic syntax rules of XML. The document is therefore not well formed and any malformed document is considered invalid (cell 3 in Table 1).
However, an XML document can be well formed yet still be invalid (cell 2 in Table 1). This occurs if the document obeys the basic XML syntax rules but violates the rules of the DTD/XSD. An example would be a well-formed TeachEngineering lesson which does not have a summary or a grade specification. Such an omission does render the document invalid, even though it is well formed.
Must All XML Have a DTD/XSD?
A question which often pops up when discussing XML and DTD/XSD is whether or not DTD/XSD are mandatory? Must we always go through the trouble of specifying a DTD/XSD in order to use XML? A related question is whether we must process a DTD/XSD to read and consume XML? The answer to both questions is ‘no,’ a DTD/XSL is not required and even if it has a DTD/XSD, there is no requirement to process that DTYD/XSD. However, if, as a data provider you make XML available to others, it is good practice to create and publish a DTD or XSD for it so that you can validate your XML before you expose it to the world. If, on the other hand, you are a consumer of XML, it is often sufficient to just read the on-line documentation of the XML web service you are consuming, and you certainly do not have to generate a DTD/XSD yourself.
Enough Theory. Time For Some Hands-on
![]()
Exercise 3.3
Point your browser to https://classes.business.oregonstate.edu/reitsma/family.xml. Notice that we have a small XML data set of a family of two people:
<?xml version="1.0" encoding="UTF-8"?>
<family>
<person gender="male">
<firstname>Don</firstname>
<lastname>Hurst</lastname>
</person>
<person gender="female">
<firstname>Mary</firstname>
<lastname>Hurst</lastname>
</person>
</family>
Let us now write a Python (3.x) program which can pick up (download) this data set and extract the information from it. (Make sure that you understand the larger picture here. Assume that instead of having a hardwired, static XML data set on the web site, we can pass the web service a family identifier and it will respond, on-the-fly, with a list of family members in XML. For instance, we might send it a request asking for the members of the Hurst family upon which it replies with the data above).
Please note that there exists a variety of ways and models to extract data from XML files or web services. Suffice it here to say that in the following Python (3.x) and JavaScript examples the XML is stored in memory as a so-called Document Object Model (DOM). A DOM is essentially a hierarchical, tree-like memory structure (we have already discussed how XML documents are hierarchical and, hence, they nicely fit a tree structure). Again, several methods for extracting information from such a DOM tree exist.
Store the following in a file called family.py and run it.
import requests
import xml.etree.ElementTree as ET
url = "https://classes.business.oregonstate.edu/reitsma/family.xml"
#Retrieve the XML over HTTP
try:
response = requests.get(url)
except Exception as err:
print("Error retrieving XML...\n\n", err)
exit(1)
#Build the element tree
try:
#Read and parse the XML
root = ET.fromstring(response.text)
except Exception as err:
print("Error parsing XML...\n\n", err)
exit(1)
#Name (tag) of root element
print("Name (tag) of root element: " + root.tag)
#Child elements of root
print("\nChild elements:")
for child in root:
print(child.tag, child.attrib)
#Access the children and grandchildren by index
print("\nChild element content by index:")
print(root[0][0].text + " " + root[0][1].text)
print(root[1][0].text + " " + root[1][1].text)
#Loop over the children and get their children
print("\nChild element content by element:")
for child in root.findall("person"):
print(f"{child[0].text} {child[1].text}: {child.attrib['gender']}")
Output:
Name (tag) of root element: family
Child elements:
person {'gender': 'male'}
person {'gender': 'female'}
Child element content by index:
Don Hurst
Mary Hurst
Child element content by element:
Don Hurst: male
Mary Hurst: female
Output:
Name (tag) of root element: family
Child elements:
person {'gender': 'male'}
person {'gender': 'female'}
Child element content by index:
Don Hurst
Mary Hurst
Child element content by element:
Don Hurst: male
Mary Hurst: female
Exercise 3.4
One of the advantages of JavaScript is that pretty much all web browsers have a JavaScript interpreter built in. Hence, there is nothing needed beyond your web browser to write and run JavaScript code. Here is the JavaScript program. Note that the JavaScript is embedded in a little bit of HTML (the JavaScript is the code within the
<script> and </script> tags):
<html>
<p id="family"></p>
<script>
var request = new XMLHttpRequest();
request.onreadystatechange = extract;
request.open("GET",
"https://classes.business.oregonstate.edu/reitsma/family.xml",
true);
request.send();
function extract()
{
if (request.readyState == 4 && request.status == 200)
{
var xmlDoc = request.responseXML;
var my_str = "";
var persons = xmlDoc.getElementsByTagName("person");
for (var i = 0; i < persons.length; i++)
{
var firstname = persons[i].childNodes[1];
var lastname = persons[i].childNodes[3];
my_str = my_str + firstname.innerHTML + " "
+ lastname.innerHTML + "<br/>";
}
document.getElementById("family").innerHTML = my_str;
}
}
</script>
</html>
You may try storing this file with the *.html extension on your local file system and then pick it up with your browser, but that will almost certainly not work because this implies a security risk.[3] To make this work, however, we installed the exact same code at https://classes.business.oregonstate.edu/reitsma/family.html and if you point your browser there, things should work just fine. (To see the HTML/JavaScript source code, right-click View Page Source or point your browser to view-source:https://classes.business.oregonstate.edu/reitsma/family.html)
TE 1.0 Documents Coded and Stored as XML
In their 1999 article in Scientific American, Bosak and Bray considered an XML-equipped web the “Next Generation Web”. With this, they meant that until that time, Web content carried in HTTP was meant to be presented to humans, whereas with XML we now had a way to present content format-free to machines. Moreover, along with XML came tools and protocols which made it relatively easy to programmatically process XML.
When we developed TE 1.0 in the early 2000s, we liked this concept so much that we decided to store all TE content in XML.
![]()
Exercise 3.5
To see this, first take a look at an arbitrary TE 1.0 activity at:
When you look at the page source in your browser (right-click: View page source), you immediately see that the page is an HTML page (the first tag is the <html> tag). This makes much sense, as the page is meant to be read by human users and hence, HTML is a good way of rendering this information in a web browser.
However, a quick look at the activity’s URL shows that the program view_activity.php is passed the parameter url which is set to the value collection/mis_/activities/mis_eyes/mis_eyes_lesson01_activity1.xml.
If we thus point our browser to: https://cob-te-web.business.oregonstate.edu/collection/mis_/activities/mis_eyes/mis_eyes_lesson01_activity1.xml, we see the actual XML holding the activity information. Each activity has 14 components: <title>, <header>, <dependency>, <time>, <activity_groupsize>, etc. Most of these are complex types in that they have one or more components of their own.
When TE 1.0 receives a request to render an activity, its view_activity.php program extracts the various components from the associated XML file, restrtuctures/formats them into HTML and serves the HTML to the requester.
view_activity.php does some other things as well. For instance, scroll down through the activity XML to the <edu_standards> tag. Notice how for this activity seven standards are defined, each with an Sxxxxxxx identifier (<edu _standard identifier=”Sxxxxxxx”>). However, when you switch back to the HTML view and look for the Educational Standards section, you find the text of those standards rather than their identifiers. How’s that done? Quite simply, really. As view_activity.php renders the activity, it extracts the <edu _standard>tags and their identifiers from the XML. It then queries a database which holds these standards with those identifiers for the associated standard texts, their grade level, their geographic origin, etc. Having received this information back from the database, it encodes it in HTML and serves it up as part of the activity’s HTML representation.
Service-Oriented Architectures and Business Process Management
Reading ‘between the lines,’ one can see a grander plan for how whole system architectures based on XML (or JSON) web services can be built: a company-wide or world-wide network of information processing software services that is utilized by software programs that connect to this network and request services from it. Service requesters and providers communicate with each other through common protocols and expose each other’s interfaces through which they exchange information (Berners-Lee et al., 2001).
One expression of this vision is what are known as Service-Oriented Architectures (SOA). MacKenzie et al. (2006) define SOA as a “paradigm for utilizing and organizing distributed capabilities that may be under the control of different ownership domains;” in other words, the distribution of software components over machines, networks and possibly organizations that are accessed as web services. Whereas in a traditional system architecture we would embed functionality within the applications that need it, in an SOA, our application software would fulfill the role of a communications officer and information integrator with most, if not all of the functionality provided by (web) services elsewhere on the network. Some of these services might run on our own machines; others can reside at third parties. Some may be freely available whereas others may be ‘for fee.’
Regardless of where these services reside and who owns them, however, they all can be accessed using some or all of the methods that we have discussed above. They exchange information in forms such as XML, they receive and send messages with protocols such as SOAP and they are self describing through the exposure of their XSD, DTD or WSDL (SOAP and WSDL are XML specifications for generalized message exchange). Hence, as long as the applications requesting their information can formulate their requests following these protocols, they can interoperate with the services.
Special update. In 2018 ―the year we published the first edition of this text― the term ‘web services’ referred to XML (or JSON) data exchange services as discussed here. Nowadays ―2022― the term ‘web service’ has been mostly replaced by ‘web endpoint,’ or ‘web API.’ There also is a lot of talk about so-called ‘micro services.’ The idea of micro services is very(!) similar to the just mentioned idea of building larger systems from small, independently functioning components that can communicate information/data with each other. The difference with ‘web services’ is that ‘micro services’ is a more general term in that it does not limit the concept to web (HTTP-based) services.
TE 1.0 Web Services Example I: K-12 Standards
As mentioned in the introductory chapter, all of TeachEngineering’s curriculum is aligned with K-12 STEM standards. Although the TE team is responsible for these alignments, it is not in the business of tracking the standards themselves. With each of the US states changing its standards, on average, once every five years and with a current total of about several 10,000s such standards, tracking the standards themselves was deemed better to be left to a third party. This party, as previously mentioned, is the Achievement Standard Network (ASN) project, owned and operated by the Desire2Learn (D2L) company.
Very much in the spirit of web services as discussed here, ASN makes its standard set available as an XML-based service.[4]
Here is a (simplified) fragment of one of ASN’s standard sets, namely the 2015 South Dakota Science standards. The fragment contains two Kindergarten (K)-level standards:
<rdf:RDF xmlns:asn="https://asn.desire2learn.com/resources/S2627378httphttps://purl.org/ASN/schema/core/" xmlns:cc="https://creativecommons.org/ns#" xmlns:dc="https://purl.org/dc/elements/1.1/" xmlns:dcterms="https://purl.org/dc/terms/" xmlns:foaf="https://xmlns.com/foaf/0.1/" xmlns:gemq="https://purl.org/gem/qualifiers/" xmlns:loc="https://www.loc.gov/loc.terms/relators/" xmlns:owl="https://www.w3.org/2002/07/owl#" xmlns:skos="https://www.w3.org/2004/02/skos/core#" xmlns:rdf="https://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:rdfs="https://www.w3.org/2000/01/rdf-schema#"> <cc:attributionURL rdf:resource="https://asn.desire2learn.com/resources/D2627218" /> <dc:title xml:lang="en-US">South Dakota Science Standards</dc:title> <dcterms:description xml:lang="en-US">The South Dakota Science Standards realize a vision for science education in which students are expected to actively engage in science and engineering practices and apply crosscutting concepts to deepen their understanding of core ideas. These standards are designed to guide the planning of instruction and the development of assessments of learning from kindergarten through twelfth grade. This document presents a starting point for informed dialogue among those dedicated and committed to quality education in South Dakota. By providing a common set of expectations for all students in all schools, this dialogue will be strengthened and enhanced. </dcterms:description> <asn:repositoryDate rdf:datatype="https://purl.org/dc/terms/W3CDTF"> 2015-05-19</asn:repositoryDate> <asn:Statement rdf:about="https://asn.desire2learn.com/resources/S2627378"> <asn:statementNotation>K-PS2-1</asn:statementNotation> <dcterms:educationLevel rdf:resource="https://purl.org/ASN/scheme/ASNEducationLevel/K" /> <dcterms:subject rdf:resource="https://purl.org/ASN/scheme/ASNTopic/science" /> <dcterms:description xml:lang="en-US">Plan and carry out an investigation to compare the effects of different strengths or different directions of pushes and pulls on the motion of an object.</dcterms:description> </asn:Statement> <asn:Statement rdf:about="https://asn.desire2learn.com/resources/S2627379"> <asn:statementNotation>K-PS2-1</asn:statementNotation> <dcterms:educationLevel rdf:resource="https://purl.org/ASN/scheme/ASNEducationLevel/K" /> <dcterms:subject rdf:resource="https://purl.org/ASN/scheme/ASNTopic/science" /> <dcterms:description xml:lang="en-US">Analyze data to determine if a design solution works as intended to change the speed or direction of an object with a push or a pull. </dcterms:description> </asn:Statement>
Notice how at the very top, the XML fragment contains a reference to the XSD that governs it (feel free to pull it up in your web browaer):
https://purl.org/ASN/schema/core/
Notice also that depending on how much we need to know about this web service, we might or might not need to analyze this XSD. If all we want to do is write a program which grabs the texts of the various standards, we do not really have to know the XSD at all. All we have to know is how to extract the <dcterms:description> elements, something which a quick study of the example shows us.
![]()
Exercise 3.6
Note how each of these two standard representations contains a link to a more human-readable representation:
https://asn.desire2learn.com/resources/Sxxxxxxx
Point your browser to each of these to see what else they hold.
TE 1.0 Web Services Example II: Metadata Provisioning
A second example of the application of web services in TE 1.0 is comprised of metadata provisioning. One of the goals of the National Science Digital Library (NSDL) project mentioned in the introductory chapter was that as a centralized registry of digital science libraries, NSDL would be up-to-date on all the holdings of all of its member libraries. For users ―or patrons in library jargon― this would mean that they could come to NSDL and conduct targeted searches over all its member libraries without having to separately search these libraries. With ‘targeted search’ we mean a search which is qualified by certain constraints. For instance, a South Dakota seventh grade science teacher might ask NSDL if any of its member libraries contains curriculum which supports standard MS-ESS3-1 (Construct a scientific explanation based on evidence for how the uneven distributions of Earth’s mineral, energy, and groundwater resources are the result of past and current geoscience processes) or for a 10th grade teacher, if there is curriculum which addresses plate tectonics which can be completed within two hours.
Two standard approaches to serve such a query come to mind. The first is known as federated search. In this approach a search query is distributed over the various members of the federation; in this case the various NSDL member libraries. Each of these members would conduct its own search and report back to the central agency (NSDL) which then comprises and sorts the results, and hands them to the original requester.
A second approach is that of the data hub in which the searchable data are centrally collected, independent of any future searches. Once a search request comes in, it can be served from the central location without involvement of the individual members.
Exercise: Compare and contrast the federated and data hub approaches to search. What are the advantages and disadvantages of each?
Since the architects of NSDL realized that it was not very likely that all its member libraries would have their search facilities up and running all the time and that they would all function sufficiently fast to support federated searches, it decided in favor of the data hub approach. This implied that it would periodically ask its member libraries for information about their holdings and centrally store this information, so that it could serve searches from it when requested. This approach, however, brings up three questions: 1. what information should the member libraries submit; 2. what form should the information be in; and 3. what sort of data exchange mechanism should be used to collect it? Having worked your way through this chapter up to this point, can you guess the answer to these questions?
- Question: What information should the member libraries submit? Possible answer: NSDL and its members should collectively decide on a standard set of data items representing member holdings.
- Question: What form should the information be in? Possible answer: XML is a good candidate. Supported by a DTD/XSD which represents the required and optional data items, XML provides a formalization which can be easily served by the members and consumed by the central entity.
- Question: What sort of data exchange mechanism should be used to collect it? Possible answer: An HTTP/XML web service should work fine.
Fortunately for NSDL and its member libraries, the second and third questions had already been addressed by the digital library world at large and its Open Archives Initiative (OAI). In 2002, OAI released its Protocol for Metadata Harvesting (OAI-PMH); an XML-over-HTTP protocol for exposing and harvesting library metadata. Consequently, NSDL asked all its member libraries to expose the data about their holdings using this protocol.
![]()
Exercise 3.7
To see OAI-PMH at work in TeachEngineering 1.0, point your browser to the following URL (give it a few seconds to generate results; the program on the other side must do all the work):
Take a look at the returned XML and notice the following:
- The OAI-PMH’s XSD is located at http://www.openarchives.org/OAI/2.0/OAI-PMH.xsd
- Collapse each of the
<record>s (click on the ‘-‘ sign in front of each of them). You will notice that only 20 records are served as part of this request. However, if you look at the<resumptionToken>tag at the bottom of the XML, you will see that the completeListSize=1581. - The reason for serving only the first 20 records is the same as Google serving only the first 10 search results when doing a Google search, namely that serving all records at once can easily bog down communication channels. Hence, if, in OAI-PMH, you want additional results, you have to issue follow-up requests requesting the next set of 20 results:https://cob-te-web.business.oregonstate.edu/cgi-bin/OAI-XMLFile-2.1/XMLFile/tecollection-set/oai.pl?verb=ListRecords&resumptionToken=nsdl!!!nsdl_dc!20[5]
- Open up the first (top)
<record>and take a look at its content. Notice how for this TeachEngineering items a variety of metadata are provided; e.g.,<dc:title>,<dc:creator>,<dc:description>,<dc:publisher>, etc. - Notice the dc prefix in each of elements listed in the previous points. This stands for Dublin Core, a widely accepted and used standard for describing library holdings.
Serving Different XML Formats with XSLT
Let us take it one last step further. We just saw how, in the model for NSDL data hub harvesting, TE (1.0) provides information on its collection’s holdings in XML over HTTP (using OAI-PMH), in Dublin Core (dc) format (indeed, quite a mouthful). But how about providing information about these same resources in other formats? For instance, IEEE developed the Learning Object Model (IEEE-LOM) format which is different from Dublin Core in that it was developed not to capture generic library resource information, but to capture learning and pedagogy-related information. If we would now want to service IEEE-LOM requests in addition to NSDL-DC requests, would we have to develop a whole new and additional XML web service? Fortunately, the answer is ‘no.. This requires some explanation. Consider the three components at work here:
- HTTP: the information transfer medium
- XML (DC, IEEE-LOM or something else): the metadata format
- OAI-PMH: the protocol for requesting and extracting the XML over HTTP
Seen from this perspective, the difference between DC, IEEE-LOM or, for that matter, any other XML representation of resource metadata is the only variable one of the three and hence, if we could easily translate between one type of XML and another, and if indeed the consumer can process OAI-PMH, we should be in business.
As it happens, the widely accepted XML translation technology called Extensible Stylesheet Language Transformations (XSLT) does just that: convert between different types of XML. The way it works is ―at least in principle― both elegant and easy. All you need to do is formulate a set of rules which express the translation from one type of XML, for instance DC, to another, for instance IEEE-LOM. Next, you need a program which can execute these translations, called an ‘XSLT processor.’ Once you have these two, all you need to do is run the processor and point it to an XML file containg the original XML and it will output the information in the other XML version.
![]()
Exercise 3.8
Once again, consider our ‘family’ XML document at: https://classes.business.oregonstate.edu/reitsma/family.xml
<?xml version="1.0" encoding="UTF-8"?>
<family>
<person gender="male">
<firstname>Don</firstname>
<lastname>Hurst</lastname>
</person>
<person gender="female">
<firstname>Mary</firstname>
<lastname>Hurst</lastname>
</person>
</family>
Now let us assume that we want to translate this into a form of XML which only holds the <firstname>s and ignores the <lastname>s; i.e., something like the following:
<?xml version="1.0" encoding="UTF-8"?> <family> <person gender="male">Don</person> <person gender="female">Mary</person> </family>
In other words, we must ‘translate’ the first form of XML to the second form of XML.
Now, consider a file containing the following XSLT translation rules:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
<xsl:output method="xml" indent="yes"/>
<xsl:template match="/family">
<family>
<xsl:apply-templates select="person"/>
</family>
</xsl:template>
<xsl:template match="person">
<person gender="{@gender}">
<xsl:value-of select="firstname" />
</person>
</xsl:template>
</xsl:stylesheet>
The file contains two rules: the first (<xsl:template match="/family">) specifies that the translation of a <family> consists of the translation of each <person> within the <family>. The second (<xsl:template match="person">) says that only a <person>’s gender and <firstname> must be copied. However, the <firstname> tag itself should not be copied.
Running this XSLT on the original XML file, we should indeed get:
<?xml version="1.0" encoding="UTF-8"?> <family> <person gender="male">Don</person> <person gender="female">Mary</person> </family>
Let us now try this.
- In a new tab, point your web browser to https://www.freeformatter.com/xsl-transformer.html
- Enter our family.xml code into the Option 1: Copy-paste your XML document here textbox.
- Enter our XSLT code into the Option 1: Copy-paste your XSL document here textbox.
- Click the Transform XML button and note the results in the Transformed Document frame
This approach, of course, suggests lots of other possibilities. Using the same technique, we can, for instance, translate from the original XML into HTML. All we have to do is modify the XSLT. Let us see if we can make Don and Mary show up in an HTML table by modifying the XSL:
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
<xsl:template match="/">
<html>
<body>
<h2>Family Members</h2>
<table border="1">
<tr bgcolor="red">
<th style="text-align:left">First name</th>
<th style="text-align:left">Last name</th>
</tr>
<xsl:for-each select="family/person">
<tr>
<td><xsl:value-of select="firstname"/></td>
<td><xsl:value-of select="lastname"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Try it and notice how we have now transformed from XML into HTML using XSLT (Dump the HTML to a file and pick it up with your web browser). Not bad, hey?
XSLT in TE 1.0
Going back to the DC/IEEE-LOM situation in TE 1.0, we might consider using DC as the base XML and writing an XSLT to translate from DC to IEEE-LOM. The problem with that approach, however, is that the DC format accommodates only a small set of attributes and, hence, many things about TeachEngineering documents cannot be easily coded in DC to start with.
This, however, suggests a different, and we think better approach. Rather than using DC or for that matter IEEE-LOM as the base XML, why not use our own TE-internal XML as a base and then use XSLT to translate to whatever format anybody ever wants? That way, we have an internal XML format that can accommodate anything we might ever have in a TE document, yet we can use XSLT technology to serve DC, IEEE-LOM or anything else. This is very much the same approach that a program such as Microsoft Excel uses to present identical data in different formats. For instance, in Excel, a number can be shown with different amounts of decimals, as a percent, as a currency, etc. Internally to the program there is only one representation of that number, but to the user this representation can be changed through a transform.
For TE, if the requester of that information can process OAI-PMH, we would have a nice XML—XSLT—OAI-PMH pipeline for serving anything as an XML web service.
So this is what we did in TE 1.0. Much to our fortune, the OAI-PMH functionality was available as the open source XMLFile package written in Perl by Hussein Suleman (2002) while at Virginia Tech. Since Suleman had already provisioned the server with means to accommodate multiple XSLTs (nice!), all we had to do was write the various XSLTs to translate from the base XML into the requested formats.
References
Allen, P. (2006) Service Orientation: Winning Strategies and Best Practices. Cambridge University Press. Cambridge, UK.
Baldwin, A.A., Brown, C.E., Trinkle, B.S. (2006) XBRL: An Impacts Framework and Research Challenge. Journal of Emerging Technologies in Accounting, Vol. 3, pp. 97-116.
Berners-Lee, T, Hendler, J., Lassila, O. (2001) The Semantic Web. Scientific American. 284. 34-43.
Bosak, J., Bray, T. (1999) XML and the Second-Generation Web. Scientific American. May. 34-38, 40-43.
MacKenzie, C.M., Laskey, K., McCabe, F., Brown, P.F., Metz, R. (2006) Reference Model for Service-Oriented Architectures 1.0. Public Review Draft 2. OASIS. http://www.oasis-open.org/committees/download.php/18486/pr-2changes.pdf. Accessed: 12/2016.
Pulier, E., Taylor, H. (2006) Understanding Enterprise SOA. Manning. Greenwich, CT.
Suleman, Hossein (2002) XMLFile. Available: http://www.husseinsspace.com/research/projects/xmlfile/. Accessed: 06/2022.
Vasudevan, V. (2001) A Web Services Primer. A review of the emerging XML-based web services platform, examining the core components of SOAP, WSDL and UDDI.
W3C (2002) Web Services Activity Statement. http://www.w3.org/2002/ws/Activity.html. Accessed: 04/07/2008
W3C (2004) Web Services Glossary. http://www.w3.org/TR/ws-gloss/#defs. Accessed: 04/07/2008
- Please note: the XML offered here is a l’improviste (off the cuff) and not at all based on a good model of music structure. It is merely meant to provide an example of how, in principle, a music score can be represented in XML. ↵
- Several competing specifications for Music XML exist. In this text we care only to convey the notion of writing an XML representation for sheet/score music and take no position on which XML format is to be preferred. ↵
- The security risk rests in the web browser running JavaScript code instructing it to reach out to an external server. This interacting of an HTTP client (the web browser) with an external source to dynamically generate content is known as Asynchronous JavaScript with XML (AJAX) technology. By default, reaching out to a server located in another domain than the one from which the original content was requested―aka Cross Origin Resource Sharing (CORS) ―is forbidden (one can easily imagine typing in a login and password which is then used to access a third party site; all in real-time from the user’s computer, yet entirely unbeknownst to the user). ↵
- Although ASN still serves standards as XML if so desired, it has recently shifted to serving them in JSON, a data exchange standard we will discuss and practice in the next chapter. ↵
- Please ignore the mysterious sequences of bangs (!) in the resumptionToken parameter. They are part of the darker recesses of OAI-PMH. ↵
