5 Relational (TE 1.0) vs. NoSQL (TE 2.0)
Introduction: Relational Is No Longer the Default MO
Whereas the coding (programming) side of system development has witnessed lots of innovation over the years, the data management side of things has long been dominated by the relational model, originally developed by E.F. Codd in the 1970s while at IBM (Codd 1970, 1982). One (imperfect) indicator of the dominance and penetration of the relational model in business IT systems is the share of coverage the relational vs. NoSQL database technologies receive in (Business) Information System Analysis and Design textbooks. Table 1 contains an inventory of a few of those books, namely the ones sitting on the shelves of one of us. Not a scientific sample, but telling nonetheless.
| Textbook | Pages relational | Pages NoSQL |
|---|---|---|
| Valacich, J.S., George, J.F., Hofer, J.A. (2015) Essentials of Systems Analysis and Design. Pearson. | Chapter 9: 45 pp. | 0 pp |
| Satzinger, J., Jackson, R., Burd, S. (2016) Systems Analysis and Design in a Changing World. CENGAGE Learning. | Chapter 9 : 35 pp. | 0 pp. |
| Tilley, S., Rosenblatt, H. (2017) Systems Analysis and Design. CENGAGE Learning. | Chapter 9: 45 pp. | 0 pp. |
| Dennis, A., Wixom, B.H., Roth, R.A. (2014) System Analysis and Design. 6th ed. John Wiley & Sons. | Chapter 6 & 11: 40 pp. | 1 pp. |
| Dennis, A., Wixom, B.H., Tegarden, D. (2012) System Analysis & Design with UML Version 2.0. John Wiley & Sons. | Chapter 9: 40 pp. | 2 pp. |
| Dennis, A., Wixom, B.H., Tegarden, D. (2015) System Analysis & Design. An Object-Oriented Approach with UML. 5th ed. John Wiley & Sons. | Chapter 9: 22 pp | 2 pp. |
| Coronel C., Morris, S. (2016) Database Systems. Design, Implementation and Management. Cengage learning. | 700+ | 11 pp. |
To be clear, pointing out the almost total absence of NoSQL coverage in these texts is not meant as a critique of these texts. The relational database remains a dominant work horse of transaction processing and hence, remains at the heart of business computing. But whereas for a very long time it was essentially the only commonly available viable option for all of business computing —transaction processing or not— new, equally viable and commonly available non-relational alternatives for non-transaction processing are making quick inroads.
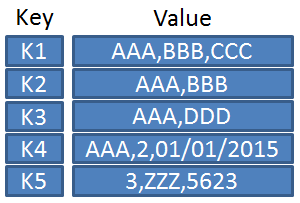
Of the six texts listed in Table 1, only Dennis, Wixom & Tegarden (2012, 2015) and Coronel & Morris (2016) give explicit attention to these non-relational or ‘NoSQL‘ options. Dennis et al. recognize three types: key-value stores, document stores and columnar stores. Key-value stores are databases which function like lookup tables where values to be looked up are indexed by a key as indicated by Figure 1. As the Wikipedia page on key-value stores shows, quite a few implementations are available these days. One of the better-known ones is the open-source implementation Riak. Columnar (or column-oriented) databases are databases which transpose the rows and columns of relational databases. Rows become columns and vice versa. This type of representation is meant to imply faster processing for what in the relational world would be column-oriented operations, which in the columnar database become row-oriented operations. Wikipedia also contains a list of implementations of this type of database.
Which brings us to the document store, a type of NoSQL database which is most relevant for us because that is what TE 2.0 uses. Document stores, aka Document Management Systems, have quite a history. Already in the 1980s several systems were commercially available to manage an organization’s paper documents, followed by systems for managing electronic documents. However, whereas these systems typically enforced their own binary representation on documents or stored the documents in their native document formats and then kept their metadata for sorting and searching, many modern NoSQL document databases store documents as text in a standard format such as XML or JSON. RavenDB and MongoDB, for example, store documents in JSON format. The fact that there typically are no constraints on the data other than these text-formatting ones is important because it implies that as long as a text complies with the format, it is considered a valid ‘document’ regardless of its information content. Hence, from the document store’s perspective, the JSON text {“foo”: “bar”} is as much a ‘document’ as a complex JSON structure representing a TeachEngineering lesson.
This notion of a document as a structured text shares characteristics with the notion of classes and objects in object-oriented programming (OOP) but also with tables in a relational database. But whereas OOP objects typically live in program memory and are stored in CPU-specific or byte-compiled binary formats, NoSQL documents exist as plain text. And whereas in relational databases we often distribute the information of an entity or object over multiple tables in order to satisfy normal form, in NoSQL document stores —as in key-value stores— we often duplicate data and neither maintain nor worry much) about the database integrity constraints so familiar from relational databases.
So, What Gives?
One might ask why these NoSQL data stores came to the fore anyway? What was so wrong with the relational model that made NoSQL alternatives attractive? And if the NoSQL databases are indeed ‘no SQL,’[1] how does one interact with them?
Let us first say that on the issue of which of these alternatives is better, the dust has by no means settled. The web is rife with articles, statements and blog posts which offer some angle, often highly technical, to sway the argument one way or the other. Yet a few generally accepted assessments can be made (refer to Buckler (2015) for a similar comparison).
- There are few if any functions which can be fulfilled by one that cannot be fulfilled by the other. Most if not everything that can be accomplished with a NoSQL database can be accomplished with a relational database and vice versa. However…
- Modern, industry-strength relational databases are very good at providing so-called ‘data consistency;’ i.e., the property that everyone looking at the data sees the same thing. Whereas such consistency is particularly important in transaction processing —a bank balance should not be different when looked at by different actors from different locations—, consistency is less important in non-transaction data processing. A good example would be pattern-finding applications such as those used in business intelligence or business analytics. A pattern is not stable —and hence, not a real pattern— if a single observation changes it. For example, when analyzing the 30-day log of our web server, any single request taken from the log should not make a difference. And if it does, we did not have a stable pattern anyway.
NoSQL databases are not always equipped with the same consistency-enforcing mechanisms as the relational ones such as locking and concurrency control. For example, in the NoSQL database RavenDB, operations on individual documents are immediately consistent. However, queries in RavenDB at best guarantee ‘eventual consistency;’ i.e., the notion that, on average or eventually, different observers see the same thing. Although eventual consistency is insufficient for transaction processing, it is often sufficient in non-transactional contexts. - Because unlike relational databases NoSQL databases are not encumbered with 40 years of engineering investments, their licenses are a lot less expensive, especially in cases where lots of data must be distributed over several or lots of different machines and different locations. Whereas that does not help when consistency is needed, it can weigh significantly if ‘eventual consistency’ is good enough.
- Relational databases enforce relational integrity (read: primary and foreign key constraints). NoSQL databases do not. But what if we are willing to sacrifice some automatic integrity checking for simpler application code or faster running programs? As we mentioned in the previous chapter, the TE 2.0 JSON representation of documents contains a lot(!) of duplicated data when compared with the TE 1.0 representation, and yet, the 2.0 system runs faster and the codes are less complicated. Of course, making a correction to all that duplicated data would require more work, but if these corrections are rare and can be accomplished without service interruption…
- NoSQL databases tend to be lightweight; i.e., no complicated and distributed client-server systems must be set up (hence, their cost advantage). However, this does not imply that complicated systems cannot be built with these systems. On the contrary, NoSQL databases are often used in highly distributed systems with multiple levels of data duplication, and complex algorithms must often be devised to retrieve information from these various locations to then be locally aggregated.
- Relational databases have predefined schemas, meaning that only specific types of data can be stored in predefined tables. NoSQL databases do not have this constraint. Referring to the JSON databases such as RavenDB and MongoDB again, one is free to store the
{“foo”: “bar”}document alongside a complex TeachEngineering lesson. One can easily conceive of some (dis)advantages either way. - So-called joins; i.e., querying data across multiple tables in a single SQL query, are the bread-and-butter of relational databases. NoSQL databases do not have joins. Of course, not having joins while having a database in normal form would mean a lot of extra programming, but since in a NoSQL database we are more than welcome to ignore normal form, not having joins does not have to be a problem.[2]
- Relational databases traditionally scale vertically by just adding more CPU’s, memory and storage space. NoSQL databases scale horizontally by adding more machines.
- Querying. Whereas SQL is the universal language for interacting with relational databases, no such language exists for NoSQL databases. Since NoSQL is not a standard, there is no standard querying protocol. Therefore, most NoSQL implementations have their own syntax and API. However, because of SQL’s installed base and popularity, some NoSQL databases offer SQL-like querying protocols. Moreover, since many software applications —databases or not— offer some sort of data retrieval mechanism, efforts to develop supra or ‘über’ query languages are underway. One example of those is Yahoo Query Language (YQL), a SQL-like language which can be used to query across Yahoo services. Similarly, Microsoft has developed its Language INtegrated Query (LINQ), a SQL-like language for programmatic querying across its .Net products.
- In this list we have not mentioned issues associated with data volume and complexity scaling and distributed computing; i.e., having to or benefiting from breaking up a ‘database’ in several or many logically united but spatially separated components. Much of the claimed benefits of NoSQL over relational databases address those issues. Although these fascinating and important issues certainly belong in database textbooks and course materials,, they are outside of the scope of our TE-specific discussion.
We also must stress that as relational and NoSQL technologies evolve, the lines between them are blurring. For instance, PostgreSQL, a mature and popular open-source relational database supports JSON as a first-class data type. This affords developers the option of using both relational and NoSQL patterns where appropriate in the same application without needing to select two separate database management systems.
TE 1.0: XML/Relational
In this section we discuss the XML/relational architecture used in TE 1.0. If you just want to learn about the TE 2.0 JSON/NoSQL version, feel free to skip this section. However, this section contains some concepts and ideas which you might find interesting, and it supports a better understanding of the relational-NoSQL distinctions.
When we designed TE 1.0 in 2002 NoSQL databases were just a research topic, and using a relational database as our main facility for storing and retrieving data was a pretty much a forgone conclusion. What was nice at the time too was the availability of MySQL; a freely available and open-source relational database.
We had also decided to use XML as the means for storing TeachEngineering content; not so much for fast querying and searching, but as a means to specify resource structure and to manage resource content validity (refer to Chapter 3 for details on XML and validity checking). Consequently, we needed a way to index the content of the resources as written by the curriculum authors into the MySQL relational database.
At the time that we were designing this indexing mechanism, however, the structure of the TeachEngineering resources was still quite fluid. Although we had settled on the main resource types (curricular units, lessons and activities) and most of their mandatory components such as title, summary, standard alignments, etc., we fully expected that components would change or would have to be added in the first few years of operations. Moreover, we considered it quite likely that in the future entirely new docuresource types might have to be added to the collection.[3] As mentioned above, however, relational databases follow a schema and once that schema is implemented in a table structure and their associated integrity constraints set up, and once tables fill with data and application codes are written, database schema changes become quite burdensome. This then created a problem. On the one hand we knew that a relational database would work fine for storing and retrieving resource data, yet the resources’ structure would remain subject to changes in the foreseeable future and relational databases are not very flexible in accommodating these changes.
After some consideration, it was decided to implement an auto-generating database schema; i.e., implement a basic database schema which, augmented with some basic application code, could auto-generate the full schema (Reitsma et al., 2005). With this auto-generation concept we mean that database construction; i.e., the actual generation of the tables, integrity constraints and indexes occurs in two steps:Remove (comment out) the foreach() loop and replace it with the following:
Console.WriteLine(resultList.Count);
- The first step consists of a traditional, hardwired schema of meta (master) tables which are populated with instructions on how the actual resource database must be constructed.
- In a second step, a program extracts the instructions from the meta tables, builds the data tables accordingly and then processes the resources, one by one, to index them into those data tables.
This approach, although a little tricky to set up, has the advantage that the entire resource database schema other than a small set of never-changing meta tables, is implemented by a program and requires no human intervention; i.e., no SQL scripts for schema generation have to be written, modified or run. Better still, when structural changes to the database are needed, all we have to do is change a few entries in the meta tables and let the program generate a brand-new database while the existing production database and system remain operational. When the application codes that rely on the new database structure are ready, just release both those codes and the new database and business continues uninterrupted with a new database and indexing structure in place.
TE 1.0 Data Tables
The following discusses a few of the data tables in the TE 1.0 database:
- Although the various resource types have certain characteristics in common; e.g., they all have a title and a summary, the differences between them gave sufficient reason to set up resource-type specific data tables. Hence, we have a table which stores activity data, one which stores lesson data, one which stores sprinkle data, etc. However, since we frequently must retrieve data across document types; e.g., ‘list all documents with target grade level x,’ it can be beneficial to have a copy of the data common to these resource types in its own table. This, of course, implies violating normal form, but such denormalization can pay nice dividends in programming productivity as well as code execution speed.
- K-12 standards have a table of their own.
- Since the relationship between TeachEngineering resources and K-12 educational standards is a many-to-many one, a resource-standard associative table is used to store those relationships. Foreign key constraints point to columns in the referenced tables.
- Since the TeachEngineering collection consists of several hierarchies of resources; for instance, a curricular unit resource referring to several lessons and each lesson referring to several activities (see Chapter 1), we must keep track of this hierarchy if we want to answer questions such as ‘list all the lessons and activities of unit x.’ Hence, we keep a table which stores these ‘parent-child’ relationships.
- TeachEngineering resources may contain links to other TeachEngineering resources and support materials as well as links to other pages on the web. In order to keep track of what we are pointing to and of the status of those links, we store all of these resource-link relationships in a separate table.
- Several auxiliary tables for keeping track of registered TeachEngineering users, curriculum reviews, keywords and vocabulary terms, etc. are kept as well.
Meta tables
To facilitate automated schema generation, two meta tables, Relation and Types were defined.
| Relation table (definition) | ||||
|---|---|---|---|---|
| Field | Type | Null | Key | Default |
| id | int(10) unsigned | NO | PRI | NULL |
| groupname | varchar(100) | NO | ||
| component | varchar(100) | NO | ||
| Relation table (sample records) | ||
|---|---|---|
| id | Groupname | component |
| 22 | Activity | cost_amount |
| 6 | Activity | edu_std |
| 72 | Activity | engineering_connection |
| 18 | Activity | grade_target |
| 21 | Activity | keywords |
| 5 | Activity | summary |
| 70 | Activity | time_in_minutes |
| 4 | Activity | title |
| 52 | child_document | link_text |
| 50 | child_document | link_type |
| 49 | child_document | link_url |
| 46 | Vocabulary | vocab_definition |
| 45 | Vocabulary | vocab_word |
| Types table (definition) | ||||
|---|---|---|---|---|
| Field | Type | Null | Key | Default |
| id | int(10) unsigned | NO | PRI | NULL |
| name | varchar(100)Remove (comment out) the foreach() loop and replace it with the following:
Console.WriteLine(resultList.Count); |
NO | ||
| expression | varchar(250) | NO | ||
| cast | enum(‘string’,’number’,’group’,’root’) | NO | string | |
| nullable | enum(‘yes”no’) | YES | YES | NULL |
| datatype | varchar(50) | YES | NULL | |
| Types table (sample records) | |||||
|---|---|---|---|---|---|
| id | name | expression | cast | nullable | datatype |
| 19 | child_document | /child_documents/link | group | NULL | NULL |
| 24 | cost_amount | /activity_cost/@amount | number | yes | float |
| 25 | cost_unit | /activity_cost/@unit | string | yes | varchar(100) |
| 6 | edu_std | /edu_standards/edu_standard | group | NULL | NULL |
| 1 | edu_std_id | /@identifier | string | yes | varchar(8) |
| 33 | engineering_category | /engineering_category_TYPE/@category | string | yes | varchar(250) |
| 14 | grade_lowerbound | /grade/@lowerbound | number | yes | int(10) |
| 13 | grade_target | /grade/@target | number | no | int(10) |
| 15 | grade_upperbound | /grade/@upperbound | number | yes | int(10) |
| 26 | keywords | /keywords/keyword | group | NULL | NULL |
| 27 | keyword | string | yes | Varchar(250) | |
Records in the Relation table declare the nesting (hierarchy) of components. For instance, an activity has a title, a summary, etc. Similarly, any reference to a child resource has a link_text, a link_type and a link_url. Note that this information is similar to that contained in the resources’ XML Schema (XSD). Essentially, the Relation table declares all the needed data tables (groupname) and those tables’ columns (component).
The Types table in its turn declares for each component its datatype, nullability as well as an XPath expression to be used to extract its content from the XML resource. For example, the cost associated with an activity (cost_amount) is a float, can be null (yes) and can be extracted from the XML resource with the XPath expression /activity_cost/@amount. Similarly, the grade_target of a resource is an int(10), cannot be null (no) and can be extracted with the XPath expression /grade/@target. Note that array-like data types such as edu_standards are not a column in a table. Instead, they represent a list of individual standards just as keywords is a list of individual keywords. They have an XPath expression but no datatype.[4]
Between the Relation and the Types tables, the entire data schema of the database is declared and as a side effect, for each column in any of the tables, we have the XPath expression to find its resource-specific value. Hence, it becomes relatively straightforward to write a program which reads the content from these two tables, formulates and runs the associated SQL create table statements to generate the tables, uses the XPath expressions to extract the values to be inserted into these tables from the XML resources, and then uses SQL insert statements to populate the tables.
What is particularly nice about this approach is that all that is needed to integrate a brand new document type into the collection is to add a few rows to the Types and Relation tables. The auto-generation process takes care of the rest. Hence, when in 2014 a new so-called sprinkle resource type was introduced —essentially an abbreviated activity— all that had to be done was to add the following rows to the Types and Relation tables:
| Records added to the Relation table to store sprinkle resource data | ||
|---|---|---|
| id | groupname | component |
| 84 | sprinkle | Title |
| 86 | sprinkle | total_time |
| 87 | sprinkle | sprinkle_groupsize |
| 88 | sprinkle | total_time_unit |
| 89 | sprinkle | grade_target |
| 90 | sprinkle | grade_lowerbound |
| 91 | sprinkle | grade_upperbound |
| 93 | sprinkle | sprinkle_cost_amount |
| 96 | sprinkle | Link |
| 97 | sprinkle | time_in_minutes |
| 98 | sprinkle | engineering_connection |
| 103 | sprinkle | Summary |
| 104 | sprinkle | dependency |
| 105 | sprinkle | translation |
| Records added to the Types table for storing sprinkle resource data | |||||
|---|---|---|---|---|---|
| id | name | expression | Cast | nullable | datatype |
| 34 | sprinkle | /sprinkle | Root | NULL | NULL |
| 35 | sprinkle_groupsize | /sprinkle_groupsize | Number | yes | int(10) |
| 36 | sprinkle_cost_amount | /sprinkle_cost/@amount | Number | yes | float |
Adding these few records resulted in the automatic generation of a sprinkle table with the requisite columns, their declared data types and nullabilities. Extraction of sprinkle information from the sprinkle XML documents to be stored in the tables was done automatically through the associated XPath expressions. Not a single manual SQL create table or alter table statement had to be issued, and no changes to the program which generates and populates the database had to be made.
TE 2.0: JSON/NoSQL
The process described in the previous section worked fine for almost 13 years during which time it accommodated numerous changes to the resources’ structure such as the addition of the sprinkle resource type. During those years the collection grew from a few hundred to over 1,500 resources. Yet when the decision was made to rebuild the system, the architectural choice of having a separate store of XML-based resources to be indexed into a relational database was questioned in light of the newly available NoSQL document databases. Why not, instead of having two more or less independent representations of the resources (XML and relational database), have just one, namely the resource database; i.e., a database which houses the resources themselves. If that database of resources can be flexibly and efficiently searched, it would eliminate a lot of backend software needed to keep the resource repository and the database in sync with each other. Better still, when rendering resources in a web browser one would not have to retrieve data from both sources and stitch it all together anymore. Instead, it could just come from a single source.
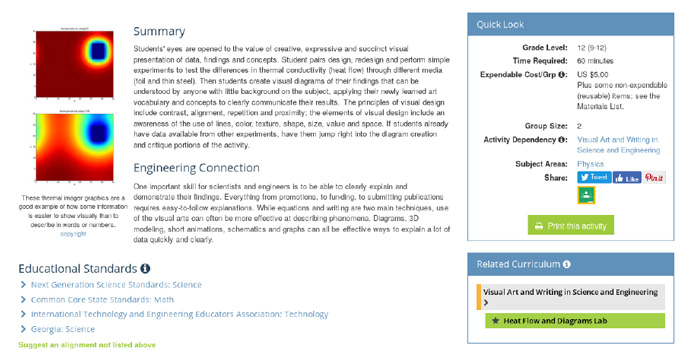
To illustrate the latter point consider the way a resource was rendered in TE 1.0. Figure 2 shows a section of an activity on heat flow. In the Related Curriculum box the activity lists its parent, the Visual Art and Writing lesson. This ‘parental’ information, however, is not stored on the activity itself because in TeachEngineering, resources declare their descendants but not their parents. In TE 1.0 we rendered this same information; i.e., the lesson from which the activity descended. However, whereas in TE. 1.0 most of the rendered information came directly from the XML resource, the resource’s parent-child information was retrieved from the database. Hence, two independent sources of information had to be independently queried and retrieved, each across networks and different computers, only to then be stitched together into a single HTML web page.
We could have, in TE 1.0, stored not just the typical lookup information of resources in the database; e.g., title, target grade, required time, summary, keywords, etc., but also the entire text of resources. Had we done that, we would have only had to access a single source of information for rendering. Except… we did not. In hindsight, perhaps, we should have?
Fast forward to 2015, TE 2.0 and the availability of NoSQL document databases such as MongoDB and RavenDB. Now, we no longer have to separate resource content from resource searching since the basic data of these databases are the resources themselves. Hence, we have everything we want to know about these resources in a single store. In addition, these databases, partly because their data structures are so simple (no multi-table normalized data structures and no referential constraints), are really fast!
Earlier in this chapter, we discussed how RavenDB provides eventual consistency for document queries. Clearly, consistency is something that requires careful consideration when designing an application. In a highly transactional application, receiving out-of-date data from queries could be quite problematic. For instance, a query on a bank account or credit card balance or on the number of available seats on a future airplane ride must be correct at all times. But for a system such as TeachEngineering, eventual consistency is just fine. Curriculum resource do not change that often, and even if they do, it is perfectly acceptable if queries return a previous version for a (limited) period of time. Similarly, when a new resource is made available it would be perfectly acceptable if that resource is not immediately available everywhere in the world. Moreover, due to the relatively small number of resources stored in TE 2.0’s RavenDB database, the’ eventual’ in ‘eventual consistency’ means in practice that queries return up-to-date results in a matter of seconds after a change to is made.
Some Practice with a JSON Document Store: MongoDB
In the remainder of this chapter we work through a practice examples using the well-known JSON document store MongoDB. We first use a very simple example of four very simple JSON documents. The example (swatches) is taken from MongoDB’s documentation pages. Next, we run a more realistic (but still very small) example of six TeachEngineering so-called ‘sprinkle’ resources. Sprinkles are abbreviated versions of TeachEngineering activities.
![]()
Exercise 5.1: Setting Up MongoDB
We will install the MongoDB 5.x (Community) Server locally. MongoDB also offers free-of-charge use of its Atlas cloud offering, but Atlas set up is more involved that installing MongoDB on a local machine which takes just a simple download and install.
We assume a Windows machine, but installs for other platforms are available as well.
- Download the MongoDB Community Server version (as msi file) from https://www.mongodb.com/try/download/community (Note: these installation instructions might be slightly different for newer versions of MongoDB).
- Run the downloaded installation script:
- Accept the license.
- Select the Complete (not the Custom) version.
- Select Run service as a Network Service user.
- Uncheck the Install MongoDB Compass option.
- Select Install.
- Finish the install.
- Find the folder where MongoDB has been installed (typically c:\Program Files\MongoDB) and navigate to its …\Server\version_no\bin folder where the executables mongod.exe and mongo.exe are stored:
- mongod.exe runs the server instance
- mongo.exe runs a Mongo command line interpreter (CLI) through which we can type and send commands to mongod.
- Use the Windows Task Manager to see if the process MongoDB Database Server (mongod.exe) is running. If not, start mongod.exe.
- By default, MongoDB relies on being able to store data in the c:\data\db folder. Either create this folder using the Windows File Browser, or pop up a Windows CLI and run the command:
mkdir c:\data\db
We will communicate with MongoDB in two modes: first, by sending it commands directly using its CLI and then programmatically using Python.
![]()
Exercise 5.2: MongoDB Command Line Interpreter (CLI)
We will run some MongoDB commands through MongoDB’s CLI. We will run without access control; i.e., without the need for a username and password.[5]
- Run mongo.exe to start a MongoDB CLI. Enter all commands mentioned below in this CLI (hit return/enter after typing the command).
MongoDB structures its contents hierarchically in databases, collections within databases and JSON records (called ‘documents’) within collections.
- Start a new database foo and make it the current database:
use foo
- Create a collection Swatches in database foo:
db.createCollection("Swatches")
Now we have a collection, we can add documents to it. We will use the swatches examples (these came directly from MongoDB’s own documentation pages).
Add four documents to Swatches using the following four commands:
db.Swatches.insertOne( { "swatch": "cotton_swatch",
"qty": 100, "tags": ["cotton"],
"size": { "h": 28, "w": 35.5, "uom": "cm" } })
db.Swatches.insertOne( { "swatch": "wool_swatch",
"qty": 200, "tags": ["wool"],
"size": { "h": 28, "w": 35.5, "uom": "cm" } })
db.Swatches.insertOne( { "swatch": "linen_swatch",
"qty": 300, "tags": ["linen"],
"size": { "h": 28, "w": 35.5, "uom": "cm" } })
db.Swatches.insertOne( { "swatch": "cotton_swatch",
"qty": 100, "tags": ["cotton"],
"size": { "h": 50, "w": 50, "uom": "cm" } })
Now, let us see what we have in Swatches using the find() command. Since we pass no criteria to find(), all documents in Swatches are returned:
db.Swatches.find()
Which swatches are made of cotton?
db.Swatches.find( { "tags": "cotton" } )
Of which swatches do we have more than 100?
db.Swatches.find( { "qty": { $gt: 100 } } )
Note how in each of these cases we provide the find() command with a pattern to match.
To close the CLI, either close the CLI window or type Cntrl-C.
![]()
Exercise 5.3: Python (3.*) — MongoDB Programmatic Interaction
Now that we have played with command-driven MongoDB, we can try our hand at having a program issue the commands for us. We will use Python (3.*) as our language, but MongoDB can be programmatically accessed with other languages as well.
Instead of hardcoding the JSON documents in our code, we will pick them up from a file. Store the following JSON in the file c:\temp\swatches.json:
[
{ "swatch": "nylon_swatch", "qty": 100,
"tags": ["nylon"],
"size": { "h": 28, "w": 35.5, "uom": "cm" } },
{ "swatch": "rayon_swatch", "qty": 200,
"tags": ["rayon"],
"size": { "h": 28, "w": 35.5, "uom": "cm" } },
{ "swatch": "suede_swatch", "qty": 300,
"tags": ["suede"],
"size": { "h": 28, "w": 35.5, "uom": "cm" } },
{ "swatch": "nylon_swatch", "qty": 100,
"tags": ["nylon"],
"size": { "h": 50, "w": 50, "uom": "cm" } }
]
To validate the syntax of the above JSON segment, check it with an on-line JSON parser such as https://jsonformatter.org/json-parser.
In order for our program to interact with MongoDB, make sure that you have the Python pymongo package installed.
Since in the previous exercise (Exercise 5.2) we already made a database (foo) with a Swatches collection, we will reuse that collection and programmatically add four swatches to it.
Here is the Python (3.*) program for inserting the four documents stored in the swatches.json file into the Swatches collection:
import json
import pymongo
#Load the JSON data from the file
#Assuming c:\temp\swatches.json -- Change if needed
json_file = "c:\\temp\\swatches.json"
try:
in_file = open(json_file, "r")
except Exception as err:
print("Error opening JSON file...", err)
exit(1)
my_json = in_file.read()
in_file.close()
#Load JSON object from the my_json string
json_data = json.loads(my_json)
#Connect to MongoDB without(!!) user credentials.
try:
my_client = pymongo.MongoClient("localhost")
except Exception as err:
print("Error connecting to MongoDB...", err)
exit(1)
#Declare the database
my_db = my_client["foo"]
#Declare the collection
my_collection = my_db["Swatches"]
#Loop through the json_data list and store each
# element (swatch) into my_collection.
for swatch in json_data:
try:
my_collection.insert_one(swatch)
except Exception as err:
print("Error inserting swatch...", err)
exit(1)
Run the program.
If you still have your MongoDB CLI open (if not, just start it again — see previous section on how to do this), let us see what the program accomplished:
use foo db.Swatches.find()
Next, we run a program which queries the Swatches collection for swatches of which we have more than 100 (qty > 100). Here is the program:
import json
import pymongo
#Connect to MongoDB without(!!) user credentials.
try:
my_client = pymongo.MongoClient("localhost")
except Exception as err:
print("Error connecting to MongoDB...", err)
exit(1)
#Declare the database
mydb = my_client["foo"]
#Declare the collection
mycollection = my_db["Swatches"]
#Query for swarches with qty > 100
try:
my_swatches = mycollection.find({"qty" : {"$gt" : 100 }})
except Exception as err:
print("Error querying swatches...", err)
exit(1)
for swatch in my_swatches:
print(swatch)
![]()
Exercise 5.4: Python (3.*) — MongoDB Programmatic Interaction: TeachEngineering Sprinkles
Now we have run through a basic (swatches) example, we can apply the same approach to a small sample of more complex but conceptually identical TE 2.0 JSON resources. Our sample contains six TE 2.0 sprinkle resources and is stored at https://classes.business.oregonstate.edu/reitsma/sprinkles.json.
Download the content of https://classes.business.oregonstate.edu/reitsma/sprinkles.json and store it in a file called c:\temp\sprinkles.json.[6]
Please take a moment to study the content of the file. Notice that it is a JSON list containing six elements; i.e., six sprinkles. Also notice that although the elements are all sprinkle resources and they all have the same structure, their elements are not always specified in the same order. For instance, whereas the third and following resources start with a Header element followed by a Dependencies element, the first two resources have their Header specified elsewhere.
First, for programmatically loading the data into MongoDB, copy the data loading code from the previous exercise (5.3). Then make the following changes:
- Set the collection to
Sprinkles - Set
json_filetoc:\\temp\\sprinkles.json
Assuming that your MongoDB server (mongod.exe) is running, running the program should load the six sprinkles into the Sprinkles collection.
Using mongo.exe, check to see if the data made it over:
use foo
db.Sprinkles.find()
Now the reverse: programmatically finding the number of sprinkles for which Time.TotalMinutes > 50. Again, we use pretty much the exact same program as we used for retrieving swatches data in Exercise 5.3, except for a few simple changes:
- Set the
collectiontoSprinkles - Replace the query with the following:
result = db.Sprinkles.count_documents({"Time.TotalMinutes" : {"$gt" : 50}}) - Print the result as follows:
print(result)
The result of running the program should be 3 (Check this against the sprinkles.json file).
Summary and Conclusion
In this chapter we took a look at how TeachEngineering evolved from a system with a relational database at its core and XML representing resources (TE 1.0), to a system running off of a NoSQL database with JSON representing resources (TE 2.0). Whereas the relational/XML model worked fine during the 13 years of TE 1.0, the new NoSQL/JSON alternative provides the advantage that JSON is used as both the resource and the database format. This unification of representation significantly reduces system complexity from a software engineering point of view.
We also argued that whereas the property of ‘consistency’ which is well entrenched in industry-strength relational databases, is of crucial importance in transactional settings, ‘eventual consistency’ is plenty good for an application such as TeachEngineering. As such, we can forgo much of the concurrency control facilities built into relational databases and instead rely on a less advanced but also much less expensive and easier to maintain NoSQL database.
Similarly, since the data footprint for a system such as TeachEngineering is not very large, replicating some data in a controlled and managed way is quite acceptable. This again implies that we can forego the mechanisms for adhering to and maintaining strict normal form, and that in turn implies that we do not need sophisticated data merge and search methods such as relational table joins.
We very much care to state that none of the NoSQL material we have discussed and practiced here deters from the value and utility of relational databases. For systems which require ‘consistency,’ relational databases with their sophisticated built-in concurrency controls continue to be a good and often the best choice. But if ‘eventual consistency’ is good enough and if one has data governance policies and practices in place which minimize the risk of data inconsistency, then one should at least consider a modern NoSQL database as a possible candidate for storing data.
References
Buckler, C. (2015) SQL vs. NoSQL: The Differences. Available: https://www.sitepoint.com/sql-vs-nosql-differences/. Accessed: 12/2016.
Codd, E. F. (1970) A Relational Model of Data for Large Shared Data Banks. Communications of the ACM. 13. 377-387.
Codd, E. F. (1982) Relational database: A Practical Foundation for Productivity. Communications of the ACM. 25. 109-117.
Dennis, A., Wixom, B.H., Roth, R.A. (2014) System Analysis and Design. 5th ed. John Wiley & Sons.
Dennis, A., Wixom, B.H., Tegarden, D. (2012) System Analysis & Design with UML Version 2.0. John Wiley & Sons.
Dennis, A., Wixom, B.H., Tegarden, D. (2015) System Analysis & Design. An Object-Oriented Approach with UML. 5th ed. John Wiley & Sons.
Reitsma, R., Whitehead, B., Suryadevara, V. (2005) Digital Libraries and XML-Relational Data Binding. Dr. Dobbs Journal. 371. 42-47.
Satzinger, J., Jackson, R., Burd, S. (2016) Systems Analysis and Design in a Changing World. CENGAGE Learning.
Tilley, S., Rosenblatt, H. (2017) Systems Analysis and Design. CENGAGE Learning.
Valacich, J.S., George, J.F., Hofer, J.A. (2015) Essentials of Systems Analysis and Design. Pearson.
- Some interpret the term NoSQL as ‘No SQL.; others interpret it as ‘Not Only SQL.’ ↵
- Although standard instructional texts on relational database design emphasize design for normal form, practitioners frequently denormalize (parts of) a relational database for the same reason; namely to write easier and/or faster code. ↵
- Although much later than originally expected, in 2014 a brand-new document type, the so-called ‘sprinkle’ was indeed added. 'Maker challenges' came a few years later ↵
- XPath is a language for extracting content from XML pages. ↵
- Note: running a database server without login and password protection is obviously not good practice. However, for our case it makes things much simpler. Just do not forget to shut down or even uninstall your Mongo server when you're done. ↵
- We could, of course, write code which retrieves the JSON over HTTP (from the given URL) rather than first storing the JSON on the local file system. However, for the sake of being able to use pretty much the exact same code as in the previous example, we will read the JSON from a local file and insert it into the database. ↵

{kind=link}