2 Why Build (Twice!) Instead of Buy or Rent?
Build, Buy or Rent?
Not very long ago, in-house or custom building of IS application systems, either from the ground up or at least parts of them, was the norm. Nowadays, however, we can often acquire systems or many of their components from somewhere else. This contrast —build vs. buy— is emphasized in many modern IS design and development texts (e.g., Kock, 2007, Valacich et al., 2016). Of course, the principle of using components built by others to construct a system has always been followed except perhaps in the very early days of computing. Those of us who designed and developed applications 20 or 30 years ago already did not write our own operating systems, compilers, relational databases, window managers or indeed many programming language primitives such as those needed to open a file, compare strings, take the square root of a number or print a string to an output device.[1] Of course, with the advances in computing and programming, an ever faster growing supply of both complete application systems and system components has become available for developers to use and integrate rather than to program themselves into their systems.
What does this mean in practice? On the system level it means that before we decide to build our own, we inventory the supply of existing systems to see if a whole or part-worth solution is already available and if so, if we should acquire/use it rather than build our own. Similarly, on the subsystem level, we look for components we can integrate into our system as black boxes; i.e., system components the internal workings of which we neither know nor need to know. As long as these components have a usable and working Application Program Interface (API); i.e., a mechanism through which other parts of our system can communicate with them, we can integrate them into our system. Note that whereas even a few years ago we would deploy these third party components on our own local storage networks, nowadays these components can be hosted elsewhere on the Internet and even be owned and managed by other parties.
Therefore, much more than in the past, we should look around for existing products and services before we decide to build our own. There are at least two good reasons for this. First, existing products have often been tested and vetted by the community. If an existing product does not perform well —it is buggy, runs slowly, occupies too much memory, etc.— it will likely not survive long in a community which scrutinizes everything and in which different offerings of the same functionality compete for our demand. The usual notion of leading vs. bleeding edge applies here. Step in early and you might be leading with a new-fangled tool, but the risk of having invested in an inferior product is real. Step in later and that risk is reduced —the product has had time to debug and refine— but gaining a strategic or temporary advantage with that product will be harder because of the later adoption. Since, when looking for building blocks we tend to care more about the reliability and performance of these components than their novelty, a late adoption approach of trying to use proven rather than novel tools, might be advisable. A good example of purposeful late adoption comes from a paper by Sullivan and Beach (2004) who studied the relationship between the required reliability of tools and specific types of operations. They found that in high-risk, high-reliability types of situations such as the military or firefighting, tools which have not yet been proven reliable (which is not to say that they are unreliable!), are mostly taboo because the price for unreliability —grave injury and death— is simply too high. Of course, as extensively explored by Homann (2005) in his book ‘Beyond Software Architecture,’ the more common situation is that of tension between software developers —Homann calls them ‘tarchitects’— which care deeply about the quality, reliability and aesthetic quality of their software, and the business managers —Homan calls them ‘marketects’— who are responsible for shipping and selling product. Paul Ford (2015), in a special The Code Issue of Bloomberg Business Week Magazine also explores this tension.
The second reason for using ready-made components or even entire systems is that building components and systems from scratch is expensive, both in terms of time and required skill levels and money. It is certainly true that writing software these days takes significantly less time than even a little while ago. For example, most programming languages these days have very powerful primitives and code libraries which we can simply use in our applications rather than having to program them ourselves. However, not only does it take (expensive) experience and skills to find and deploy the right components, but combining the various components into an integrated system and testing the many execution paths through such a system takes time and effort. Moreover, this testing itself must be monitored and quality assured which increases demands on time and financial resources.
Nowadays, a whole new dimension of the ‘build or buy’ issue has been added: security. Sadly, an ever growing army of ill-willing, malevolent actors is continuously attacking our systems, trying to steal information, use our machines as bridgeheads for attacks on other machines, submit us to blackmail, spy on us or hurt us just for the fun of it. This means that we must spend increasing amounts of resources on protecting our digital assets from these people and their evil. In fact, when we think of this, we quickly realize that the massive investments in cybersecurity in the last 10 years or so are almost entirely zero ‘value-add,’ meaning that these are costs which are incurred but which do not add value to a product. This makes one wonder how much more we could have accomplished if we did not have had to ‘waste’ all these resources on protecting us from the ‘bad guys.’
Regardless, cybersecurity is an everyday issue in today’s computing and must therefore be accounted for in de development of our systems. From the ‘build or buy’ perspective this means that we either must ourselves build safety into our programs (build), or we must trust that such safety is built into the services and products we acquire from others (buy).
So Why Was TeachEngineering Built Rather Than Bought… Twice?
When TE 1.0 was conceived (2002), we looked around for a system which we could use to store and host the collection of resources we had in mind, or on top of which we could build a new system. Since TE was supposed to be a digital library (DL) and was funded by the DL community of the National Science Foundation, we naturally looked at the available DL systems. At the time, three more or less established systems were in use (we might have missed one; hard to say):
- DSpace, a turnkey DL system jointly developed by Massachusetts Institute of Technology and Hewlett Packard Labs,
- Fedora (now Fedora Commons), initially developed at Cornell University, and
- Perseus, a DL developed at Tufts University.
Perseus had been around for a while; DSpace and Fedora were both new in that DSpace had just been released (2002) and Fedora was fresher still.
Assessing the functionality of these three systems, it quickly became clear that whereas they all offered what are nowadays considered standard DL core functions such as cataloging, search and metadata provisioning, they offered little else. In particular, unlike more modern so-called content and document management systems, these early DL systems lacked user interface configurability which meant that users (and those offering the library) had to ‘live’ within the very limited interface capabilities of these systems. Since these were also the days of a rapidly expanding world-wide web and a rapidly growing toolset for presenting materials in web browsers, we deemed the rigidity and lack of flexibility and API’s of these early systems insufficient for our goals.[2]
Of course, we (TeachEngineering) were not the only ones coming to that conclusion. The lack of user interface configurability of these early systems drove many other DL initiatives to develop their own software. Good examples of these are projects such as the Applied Math and Science Education Repository (AMSER), the AAPT ComPADRE Physics and Astronomy Digital Library, the Alexandria Digital Library (ADL) , the (now defunct) Digital Library for Earth System Education (DLESE) and quite a few others. Although these projects developed most of their own software, they still used off-the-shelf generic components and generic shell systems. For instance, ComPADRE used ColdFusion, a web application platform for deploying web page components. Likewise, most of these systems rely on database software acquired from database management system makers such as Oracle, IBM, or others, and all of them rely on standard and generic web (HTTP) servers for serving their web pages. As for TE 1.0, it too used quite a few standard, third party components such as the Apache HTTP web server, the XMLFile program for serving metadata, the MySQL relational database, Altova’s XMLSpy for formulating document standards, the world-wide web consortium’s (W3C) HTML and URL (weblink) checkers, and a few more. Still, these earlier DL systems contained a lot of custom-written code.
What About TE 2.0?
In 2015, it was decided that the TE 1.0 architecture, although still running fine, was ready for an overhaul to make it more flexible, have better performance, use newer coding standards, increase security and provide better opportunities for system extensions as well as some end-user modifiability. Between 2002 (TE 1.0 conception) and 2015 (TE 2.0 conception), information technology advanced a great deal. Machines became a lot faster, new programming languages were born and raised, nonrelational databases made a big comeback, virtual machines became commonplace and ‘the cloud’ came alive in its various forms such as Software as a Service (SaaS) and Platform as a Service (PaaS). Another significant difference between the 2002 and 2015 Web technology landscapes was the new availability of so-called content management frameworks (aka content-management systems or CMS). Although less specific than the aforementioned DL generic systems, these systems are aimed at providing full functionality for servicing content on the web, including user interface configurability. One popular example of such a system is Drupal, a community-maintained and open-source CMS which in 2015 was deployed at more than one million websites including the main websites of both our institutions, Oregon State University and the University of Colorado, Boulder.[3] We, therefore, should answer the following question. If at the time of TE 2.0 re-architecting these CMS’s were broadly available, why did we decide to once again build TE 2.0 from the ground up rather than implementing it in one of these CMS’s?
Indeed, using one of the existing open-source content management systems as a foundation for TE 2.0 would have had a number of advantages. The most popular content management systems: WordPress, Joomla and Drupal, have all been around for quite some time, have active development communities and have rich collections of add-in widgets, APIs and modules for supplementing functionality. In many ways, these content management systems provide turn-key solutions with minimal to no coding required.
Yet, a few concerns drove us towards building TE 2.0 rather than using an existing CMS as its foundation. Out of the box, CMS’s are meant to facilitate the publishing of loosely structured content in HTML form. TE curricular documents, on the other hand, are very structured. As discussed in the previous chapter, each document follows one of five prescribed templates containing specific text sections along with metadata such as grade levels, educational standards, required time, estimated cost, group size, etc. Curriculum documents are also hierarchically related to each other. For example, curricular units can have (child) lessons, which in turn can have (child) activities (Figure 1).
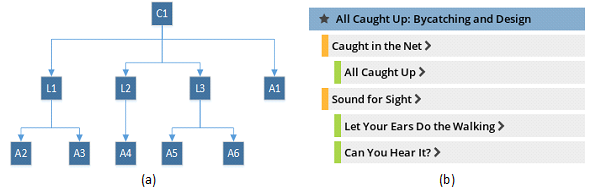
It would of course have been possible to customize any of the popular content management systems to work with this structured data. However, customizing a content management system requires a developer to not only be familiar with the programming languages, databases, and other tools used to build the CMS, but also its Application Programming Interfaces (APIs) and extensibility points. This steepens the learning curve for developers.
Second, since the development of the popular CMS’s in the early 2000’s, so-called schema-free NoSQL document databases have emerged as powerful tools for working with structured and semi-structured data of which TE curricular documents are a good example[4]. CMS support for document databases was limited in 2015. Of the “big three” mentioned earlier, only Drupal listed limited support for a single document database (MongoDB).
Third, although CMS’s increasingly allow developers to give the systems their own look and feel, they do enforce certain conventions and structures. These apply to screen layout and visual components, but also to how the CMS reaches out to external data sources and how end users interact with it. Although this by no means implies that one could not develop a TE-like system within these constraints, being free from them has its advantages. Whereas for content providers with limited coding and development capabilities these constraints represent a price well worth paying in exchange for easy-to-use, predefined layout options, for providers such as the TE team staffed with professional software developers, the reverse might be the case.
Finally, the three most popular content management systems were built using the PHP programming language. TE 2.0 was developed at the Integrated Teaching & Learning Laboratory (ITLL) at the University of Colorado, Boulder. ITLL had two full-time software developers on staff and the other software it develops and supports is primarily based on the Microsoft .Net platform. Given the small size of the development team, there was a strong desire to not introduce another development programming stack to first learn and master, then support and maintain. While there were a few fairly popular content management systems built on the .Net platform, for example, Orchard and DotNetNuke, they do not have nearly the same level of adoption as the content management systems built on PHP.
Still despite of TE 2.0 once again having been rebuilt from the ground up, it relies quite heavily on external services, especially when compared with TE 1.0. Table 2.1 contains a side-by-side of a number of functions present in both TE 1.0 and TE 2.0. The ones rendered in green are outsourced to external service providers.
| TE 1.0 (2003 – 2016) | TE 2.0 (2016 – present) |
|---|---|
| On-site, self-managed Apache web server | Azure-managed IIS web server |
| On-site, self-managed MySQL database | Cloud-managed RavenDB service |
| Google site search | Azure Search |
| On-site, self-managed Open Journals System | Cloud-managed Open Journals System service |
| Achievement Standard Network XML service | Achievement Standard Network JSON service |
| Google Analytics | Google Analytics |
| No social networking | Cloud-managed AddThis service |
| On-site commenting and customer feedback system | Cloud-managed LinkEngineering service Cloud-managed Disqus commenting service |
| No email marketing |
Cloud-managed MailChimp |
A Word on Open Source
A question we are sometimes asked is whether we could have (re)built TE open source and whether or not TE is open source?
The first question is easier to answer than the second. No, we do not think that TE, or most systems for that matter, could have initially been developed as open source. The typical open source model is that the initial developer writes a first, working version of an application, then makes it available under a free or open source software (FOSS) license and invites others to contribute to it. Two classic examples are the GNU software collection and the Linux kernel. When Richard Stallman set out in 1983 to build GNU, a free version of the Unix operating system, he first developed components himself and then invited others to join him in adding components and improving existing ones. Similarly, when Linus Torvalds announced in August 1991 that he was working on the Linux kernel, he had by then completed a set of working components to which others could add and modify. More recent examples are the Drupal CMS mentioned earlier, open sourced by Dries Buytaert in 2001, and .NET Core, Microsoft’s open source version of .NET released in 2016. In each of these cases, a set of core functionality was developed prior to open sourcing them.
The straight answer to the second question —is TE open source?— is also ‘no,’ but only because we estimate that open sourcing is more work than we are willing to take on, not because we do not want to share. It is important to realize that open sourcing a code base involves more than putting it on a web or FTP site along with a licensing statement. One can do that, of course, and it might be picked up by those who want to try or use it. However, accommodating changes, additions, and documentation requires careful management of the code base and this implies work which until now we have hesitated to take on.
Exercise 2.1: Build or Buy? – The $150/Year Case
The following recounts a real-world case of engineering, business and administrative perspectives clashing. It shows how, when making build-or-buy decisions, the world can look rather different depending on the perspective through which that world is seen.The Players
- Project Lead (PL)
- External Software Development Team (SDT)
- Infrastructure / systems supervisor and assistant (IT)
- Cloud Services Provider (CSP)
The Context
A $3M, 3-year project overseen and lead by the PL. One of the components of the project is the development of a data visualization application. The development of the visualization application has been outsourced to an external SDT at a cost of $165K. Once the development is complete, the application must be hosted on the systems of the organization running the project.
The Problem — Part 1
The software development team has completed the development and testing of the data visualization app. The application is computationally intensive (requires lots of CPU cycles). They have developed it on a VM running on the systems of their own organization. The VM was set up as having two (2) single-core CPUs and 16 GB of memory. The application seems to run fine, with good performance, even on the largest of test cases. The SDT has not spent all of its budget; about 25% of the budget is remaining. The SDT has lots of ideas for additional functionality and collection of usage data.
The project’s organization does not host any of its applications on its own computers; virtualized or otherwise. Instead, they deploy all their applications using an external CSP. Following that model, IT sets up a VM at the CSP to run the visualization app. The VM is of the least expensive option: one (1) single-core CPU and 1.75 GB of memory. Cost per month: $12.50.
As soon as the system is running, the SDT runs some tests and notices that the application performs very poorly on larger, more computationally intensive test cases. In fact, they discover that while these cases run, all other requests coming in for that same service —even the ones which would not require much memory or CPU time— are queued up and have to wait until the original, large test case has completed. Since actual users will expect a result within a few seconds, the SDT considers this unacceptable and contacts IT to see what can be done about this.
After running its own tests, IT assesses that the problem almost certainly lies with the limited capacity of the VM. They suggest that the SDT work around the problem by modifying the application so that it pre-caches computationally expensive cases. In other words, they suggest additional development of a module that anticipates those large cases, precomputes their solutions during times of low demand, stores (caches) those solutions and then simply returns those (precomputed and cached) solutions whenever they are requested, rather than computing them on the fly.
Whereas the SDT considers this an intriguing suggestion, they react not by embarking on this caching approach, but instead by asking the project organization what it would cost to upgrade the VM. IT answers that the CSP offers doubling the VM’s capacity —two (2) single-core CPUs and 3.5 GB of memory— at $25 per month. However, they do not offer to buy that upgrade. Instead, they insist on the SDT developing the caching module.
Question Set 1 (please think about/answer this before(!!) you move on to the second part of this problem.
- Why did the SDT ask for upgrading the VM rather than embarking on the development of a caching module? When thinking about this, consider that the SDT pays its (student) developers $18/hr. Hint: it is not just development cost that the SDT has in mind.
- Why would IT not offer to buy the VM upgrade, but instead insist on the SDT developing the caching module?
- Why might the project organization not ‘spin up’ its own VM and host the application on it, especially since it has plenty of computing capacity?
- If we assume that both the project organization and the SDT want the application to be a success, what course of action do you recommend at this point?
The Problem — Part 2
After some back-and-forth, IT decide to buy the VM upgrade at a cost of $25/month ($300/year). They also note that the CSP offers doubling the VM capacity once again at a doubling of the price ($600/year) but state that it will not do that without explicit permission of the PL. The SDT thanks IT for the VM upgrade.
Question 2
What should be done if the initial upgrade does not prove sufficient and large cases continue to run slow? Think of some options and consider the pros and cons of those options for each of the parties involved.
References
Ford, P. (2015) The Code Issue. Special Issue on Programming/Coding. Bloomberg Business Week Magazine. June 2015.
Homann, L. (2005) Beyond Software Architecture. Addison-Wesley.
Sullivan, J. J., Beach, R. (2004). A Conceptual Model for Systems Development and Operation in High Reliability Organizations. In: Hunter, M. G., Dhanda, K. (Eds.). Information Systems: Exploring Applications in Business and Government. The Information Institute. Las Vegas, NV.
- One of us actually wrote a very simple window manager in the late 1980s for MS-DOS, Microsoft’s operating system for IBM PCs and like systems. Unlike the more advanced systems at the time such as Sun’s SunView, Apple’s Mac System, and Atari’s TOS, there was no production version of a window managing system for MS-DOS. Since our application at the time could really benefit from such a window manager, we wrote our own (very minimal) version loosely based on Sun’s Pixrect library. ↵
- Important note. In Beyond Software Architecture Homann (2005) refers to a phenomenon known as résumé-driven design. With this he means that system designers may favor design choices which appeal to them from the perspective of learning or exploring new technologies. Similarly, since system designers and software engineers are in the business of, well…, building (programming) systems, they may be predispositioned to favor building a system over using off-the-shelf solutions. For reasons of full disclosure, both of us were not disappointed in —and had some real influence on— the decision to build rather than to buy. ↵
- To detect if a website is Drupal based, point your web browser to the website and display the page’s HTML source code (right-click somewhere in the page —> View Page Source). Drupal pages contain the generator meta tag with its content attribute set to Drupal x where x is the Drupal version number. ↵
- An important difference between TE 1.0 and TE 2.0 is the switch from a relational (SQL) database backend to a NoSQL backend. We extensively discuss this switch in later chapters ↵
