6 Resource Accessioning
Introduction
All libraries, digital or not, have processes for formally accepting and including items into their collection; a process known as ‘accessioning,’ and for removing items from their collection known as ‘deaccessioning.’ In this chapter we contrast and compare the accessioning methods of TE 1.0 and 2.0. We will see that, once again, the choice of XML vs. JSON, although not strictly a cause for difference in accessioning approaches, almost naturally led to differences between the two architectures. The most significant of these differences is that whereas in TE 1.0 resource editing and accessioning where two separate processes executed and controlled by different people, in TE 2.0 they became integrated into a single process executed by the resource editor.
Authoring ≠ Editing
One way in which we can categorize digital libraries is by distinguishing ‘content collections’ from ‘meta collections.’ In a meta collection, no actual content is kept; only meta data —data about content— are kept. A good example of a meta collection is NSDL.org. NSDL (or National Science Digital Library) maintains meta data of about 35 digital library collections and allows searches over those 35 collections. The actual resources themselves, however, are held by the various collections over which NSDL can search.
For meta collections, accessioning tends to be a relatively simple process, mostly because each resource they hold —a so-called meta record— tends not to contain much data. In fact, in many cases this accessioning is fully or semi-automated in that it can be entirely accommodated with web services offered by the various libraries which allow their meta data to be collected by the meta collection. Of course, the main difficulty for meta collections is to keep them synchronized with the content collections they reference. Resources newly added to the content collections must be referenced, without too long a delay, in the meta collection, and documents no longer available in the content collections must be dereferenced or removed from the meta collection.
For content collections, however, accessioning tends to be more complicated, partly because the resources to be accessioned are more complicated and partly because they often have to be reformatted.
TeachEngineering documents —in both TE 1.0 and TE 2.0— are typically submitted by their authors as text-processed documents; most often Microsoft Word documents. Their authors are neither asked nor required to maintain strict formatting rules, but they are required to provide specific types of information for specific types of content such as a summary, a title, grade levels, etc. Depending on the type of resource, entire text sections are either mandatory or optional. TeachEngineering lessons, for instance, must have a Background section and activities must have an Activity Procedure section. TeachEngineering resource editors work with the authors to rework their documents so that they comply with the required structure. Once done, however, the resources are still in text-processed form. Hence, as we have learned in the previous chapters, the first step of accessioning consists of converting them from text-processed form into the format required by the collection: XML for TE 1.0; JSON for TE 2.0. This conversion is done by special TeachEngineering editing staff known internally as ‘taggers.’[1]
TE 1.0 Tagging: Not Quite WYSIWYG XML
As discussed in the previous chapters, all TE 1.0 resources were stored as XML. Hence, conversion of their content as written by their authors to TE-specific XML was the main objective of the tagging process. This constituted a problem because the TE-XML specification was complex and asking taggers to themselves apply the proper tags to resource content would almost certainly lead to difficulties. Moreover, as mentioned in chapter 3, the TE XML contained both content and some formatting tags. This mixing of tag types and the myriad of validation rules associated with these tags made it essentially impossible for student workers —the TE 1.0 tagging staff consisted mainly of student workers— to directly edit the resources in XML.
Of course, we as TeachEngineering were not the only ones having this problem. With the rapidly increasing popularity of XML came the common need to convert resources from one form or another into XML, and this task is not very human friendly.
Fortunately, Altova, a company specializing in XML technology made available (for free) its Authentic tool for in-document, what-you-see-is-what-you-get (WYSIWYG) editing of XML documents. With Authentic, TE taggers could view and edit TE resource documents without having to know their XML, yet Authentic would save their resource in TE-XML format. Moreover, since Authentic kept track of the TE-XML Schemas —recall that an XML schema is the specification of the rules of validity for a particular type of XML document— it protected taggers from violating the Schema, thereby guaranteeing that documents remained valid.
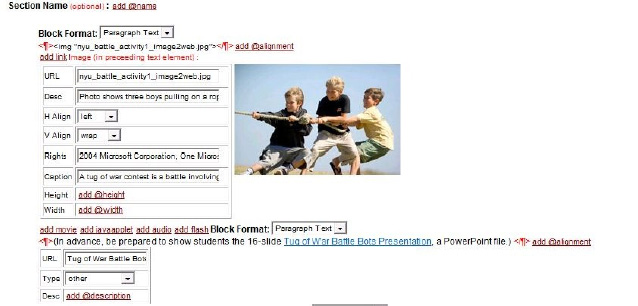

Figure 1 shows part of a TE 1.0 activity edit session using Authentic. Note how the look-and-feel of the activity as seen in Authentic is different from the look-and-feel of that same activity when rendered in TE 1.0 (Figure 2). There are two reasons for this difference. First and foremost, XML is (mostly) about content and content can be rendered in many different ways. Second, because XML is (mostly) about content, no great effort was neither made nor needed to precisely render the activity in Authentic as it would render in TeachEngineering. Still, in order to show a tagger the rendered version of the resource, the TE 1.0 system offered a (password-protected) web page where the tagger could test-render the resource.
You might, at this point, be wondering who then determines the look-and-feel of the Authentic version of the document and how that look-and-feel is set up? This would be a good question and it also points out the cleverness of Altova’s business model. In a way, Altova’s business model associated with Authentic is the reverse of that of Adobe’s business model associated with its PDF Reader. Adobe gives away PDF Reader as a loss leader so that it can generate revenue from other PDF-processing products. Demand for these products would be low if few people can read what comes out of them. With Authentic we have the reverse situation. Altova sells tools for generating and validating XML Schema’s. One of the uses of those schemas is for people to edit documents in XML which follow those schemas. So Altova makes the Authentic XML editor available free of charge but generates revenue with the tools that produce the files —XSDs and Authentic WYSIWIG document layouts— with which documents can be edited in Authentic. Hence, in TE 1.0, the TE engineers used Altova tools to construct the resource XSDs and to generate a layout for WISYWIG editing in Authentic. TE taggers then used the free-of-charge Authentic tool to do the actual document editing and used a TeachEngineering test-rendering service to see the rendered version of the edited document.
TE 1.0 Document Ingestion and Rendering
Although XML editing of the resource was the most labor-intensive step of the accessioning process, once we had an XML version of a TE resource, we were not quite there yet as it still had to be registered to the collection. In TE 1.0 this was done in three steps.
- Resource check-in. The tagger would check the resource into a central code repository (aka version control) system. Code repository systems such as Subversion and Git maintain a history and a copy of all code changes, allow reverting to previous versions of the code, track who made which change when, and can checkpoint whole collections of code in so-called code branches or releases. They are indispensable for code development, especially when more than one coder is involved.Although developed for managing software source code, these systems can of course also be used for tracking and maintaining other types of electronic data sets, for instance XML or JSON files. Hence, in TE 1.0, taggers, once a resource had been converted to XML, checked that resource into a central code repository system.
- Meta data generation. Once checked into the code repository system, a program run once or twice a day would extract data from the XML resources and generate meta data for them. Recall from chapter 3 that these meta data were served to third party users interested in TeachEngineering contents. One of those was NSDL.org whose data-harvesting programs would visit the TeachEngineering meta data web service monthly to inquire about the state of the collection. A side effect of this meta data generator, however, was additional quality control of the content of the resource. As we have seen, XSDs are an impressive quality control tool as they can be used to check the validity of XML documents. Such validity checking, however, is limited to the syntax of the document. Hence, a perfectly valid XML document can nevertheless have lots of problems. For example, it may contain a link to a non-existing image or resource or it may declare a link to a TE lesson whereas in fact the link points to an activity. One of the things that the meta data generator did, therefore, was to conduct another set of quality control checks on the resources. If it deemed a resource to be in violation of one or more of its rules, no meta data would be generated for it and the resource would not be ingested into the collection. It would, of course, remain in the code repository system from which the tagger could then check it out, fix the problem(s) flagged by the meta data generator and check it back in for the next round of meta data generation.
- Document indexing. Twice daily TE 1.0 ran a process which would actually ingest newly created or modified resources. We named this process ‘the spider’ because its method of picking up resources for ingestion was very similar to that of so-called web crawlers, aka ‘web spiders.’ Such a crawler is a process which extracts from a resource all the data it is looking for, after which it then looks for references or links to other resources and then crawls those in turn. Whereas most modern crawlers are multi-threaded; i.e., they simultaneously crawl more than one resource, the TE 1.0 spider was simple and processed only one resource at the time. This was perfectly acceptable, however, because although the overall process would complete more quickly if crawls would run in parallel, we only had to complete the process twice a day. Figure 3 shows the process of ‘spidering’ a TE 1.0 resource; in its generic form as pseudo code (a) and as an example of spidering a TE 1.0 curricular unit on heart valves (b). Note how the process in (a) is recursive, i.e., the spider() method contains a call to spider().
Figure 3: TE 1.0 document spidering. Generic algorithm (a) and Curricular Unit example (b). Id Example (a) spider (document) { document.index_content(); // index the document doc_links = document.find_links(); // find links in the // document foreach (doc in doc_links) // spider all doc_links if (spidered(doc) == false) // only spider when // not yet spidered spider(doc); }(b) Curricular Unit: Aging Heart Valves: - Lesson: Heart to Heart:
- Activity: The Mighty Heart
- Activity: What’s with all the pressure?
- Lesson: Blood Pressure Basics:
- Activity: Model Heart Valves
0. Spider curricular unit:
Aging Heart Valves:
Index content of Aging Heart Valves
Doc_links found:
Lesson: Heart to Heart
Lesson: Blood Pressure Basics
1. Spider lesson: Heart to Heart:
Index content of Blood Pressure Basics
Doc_links found:
Activity: The Mighty Heart
Activity: What’s with all the pressure?
1a. Spider activity The Mighty Heart:
Index content of The Mighty Heart
Doc_links found: none
1b. Spider activity What’s with all the pressure?:
Index content of What’s with all the pressure?
Doc_links found: none
2. Spider lesson: Blood Pressure Basics:
Index content of Blood Pressure Basics
Doc_links found:
Activity: Model Heart Valves
2a. Spider activity Model Heart Valves:
Index content of Model Heart Valves
Doc_links found: none
- Lesson: Heart to Heart:
- Document rendering. One last step in the resource production chain in both TE 1.0 and 2.0 is actual rendering of a resource in users’ web browsers. To a large extent, this is the simplest of the production steps, although it too has its challenges. Rendering in TE 1.0 was accomplished in PHP, then one of the more popular programming languages for web-based programming.
Rendering a TE 1.0 document relied partly on information stored in a document’s XML content and partly on information stored in the database generated during resource indexing. Whereas all of the resource’s content could be rendered directly from its XML, some aspects of rendering required a database query. An example is a resource’s ‘Related Curriculum’ (Figure 4). Whereas a resource may have ‘children;’ e.g., a lesson typically has one or more activities, it does not contain information about its parents or grandparents. Thus, while a lesson typically refers to its activities, it does not contain information as to which curricular unit it belongs. A resource’s complete lineage, however, can be constructed from all the parent-child relationships stored in the database and hence a listing of ‘Related Curriculum’ can be extracted from the database, yet not from the resource’s XML.
Figure 4: TE 1.0 rendering of The Mighty Heart activity’s ‘Related Curriculum.’ A second example of database-reliant resource rendering in TE 1.0 concerns a resource’s educational standards. Figure 5 shows the list of K-12 science and engineering standards to which the activity The Mighty Heart have been aligned.

Figure 5: TE 1.0 rendering of The Mighty Heart activity’s aligned engineering and science educational standards. Because the relationship between educational standards and resources is a so-called many-to-many one (a standard can be related to multiple resources and one resource can have multiple standards), in TE 1.0 standards were stored uniquely in the database and resources referred to those standards with standard IDs. For The Mighty Heart activity, the associated XML was as follows[2]:
<edu_standards> <edu_standard identifier="S11326BD"/> <edu_standard identifier="S11326BE"/> <edu_standard identifier="S11416DF"/> </edu_standards>Hence, it is clear that in order to show the information associated with the standard (text, grade level(s), issuing agency, date of issuance, etc.), it must be retrieved from the database rather than from the referring resource.
TE 2.0 Tagging: Much More WYSIWYG JSON
While the TE 1.0 tagging process served the TeachEngineering team well, it had a few notable downsides.
-
The Authentic software to write (tag) the resources in XML needed to be installed on each editor’s computer along with the XML schema for each type of curriculum resource.
-
The editing workflow had a number of steps that required the editor to understand specialized software, including Authentic and the Subversion version control system.
-
Previewing a rendered resource required the editor to upload the resulting XML file to the TE site.
-
The fact that the spider ran only twice a day limited how quickly new resources (and edits to existing resources) appeared on the site.
One of the goals with TE 2.0 was to streamline the tagging and ingestion process. Since TeachEngineering is a website, the logical choice was to allow taggers to add and edit documents from their web browser; no additional software required. As such, TE 2.0 includes a web/browser-based resource editing interface that is very similar to that of modern more generalized content management systems such as WordPress (Figure 6)
The JavaScript and HTML open source text editor TinyMCE, a tool specifically designed to integrate nicely with content management systems, was used as the browser-based editor. TinyMCE provides an interface that is very similar to a typical word processor.
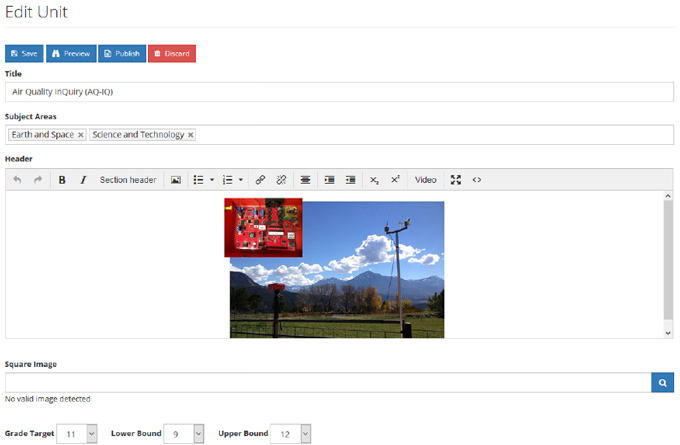
Figure 6 shows an example of editing a resource in TE 2.0. The interface provides a few options to support the editor’s workflow. The Save button saves the in-progress resource to the (RavenDB) database. Resources that are in a draft state will not be visible to the public. The Preview button shows what the rendered version of the resource will look like to end users. The Publish button changes the resource’s status from draft to published, making it publicly visible. Any errors in the resource, such as forgetting a required field are called out by displaying a message and highlighting the offending field with a red border. Publishing of a resource which violate content rules is impossible.
As in the case of TE 1.0, resources in TE 2.0 are hierarchically organized in that resources specify their children; e.g., a lesson specifying its activities, or a curricular unit specifying its lessons. But whereas in TE 1.0 editors had to specify these children with a sometimes complex file path, in TE 2.0, they have a simple selection interface for specifying these relationships and are no longer required to know where resources are stored on the file system (Figure 7).
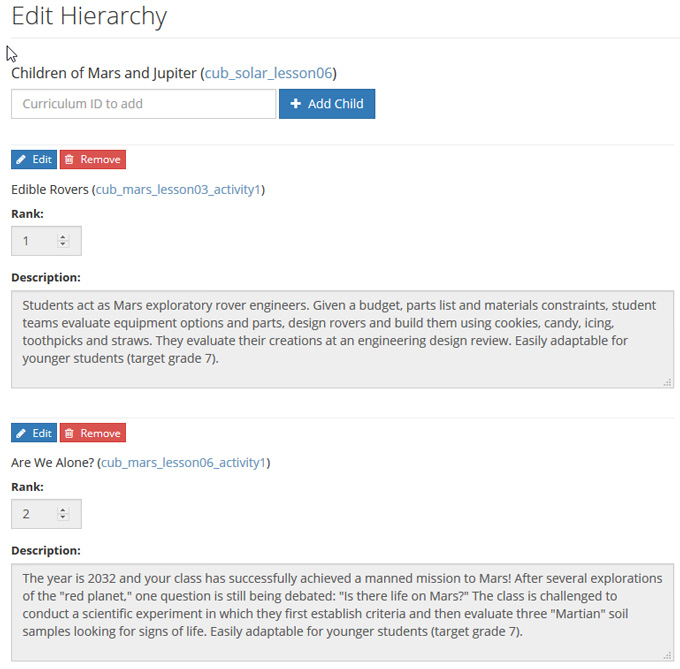
One other noteworthy difference between TE 1.0 and TE 2.0’s tagging processes is that with TE 1.0, content editors by necessity had to have some knowledge of the internal structure and working of TeachEngineering’s architecture. They had to create resources using Authentic, and check the resulting XML resource into a version control system. With TE 2.0, editors edit resources using a familiar almost-WYSIWYG interface. The software behind the scenes takes care of the technical details of translating the resources into JSON and storing them in the RavenDB database.
TE 2.0 Document Ingestion and Rendering
With TE 2.0’s architecture, the resource ingestion and rendering process is greatly simplified. Here we will revisit the ingestion and rendering steps from TE 1.0 and contrast them with the process in TE 2.0.
- Resource check-in. In TE 2.0, there is no resource check-in process; i.e., no process of moving files from the local system into the TE repository of resource. When taggers save the resource, it is stored in RavenDB as JSON.
- Meta data generation. In TE 2.0, there is no separate meta data generation process. As noted in chapter 4, TE 2.0 neither generates nor stores meta data. The JSON representation of the curriculum resource is the single version of the TE reality. Whereas TE 1.0 always generated and exposed its meta data for harvesting by meta collections such as the National Science Digital Library (NSDL), TE 2.0 no longer does this. This is mostly because the support for and use of generic meta data harvesting protocols such as OAI-PMH (Open Archive Initiative–Protocol for Metadata Harvesting) have dwindled in popularity.
- Resource indexing. There is no separate resource indexing step in TE 2.0. Since resources are saved directly to RavenDB, RavenDB will itself re-index its resources. Hence, there is no need to crawl and discover new or modified resources.
- Resource rendering. At a high level, the resource rendering process in TE 2.0 is quite similar to TE 1.0’s process, with a few key differences. For one thing, TE 2.0 was developed in C# as opposed to TE 1.0’s PHP.
Whereas in TE 1.0 the hierarchical relationships between any pair of resources were stored as parent-child rows in a relational database table, in TE 2.0, the relationship between all of the curriculum resources are stored in RavenDB in a single JSON document. This tree-like structure is cached in memory, providing a fast way to find and render a resource’s relatives (ancestors and descendants). For example, a lesson will typically have one parent curricular unit and one or more child activities. The following is an en excerpt of the JSON document which describes the relationship between resources.{ "CurriculumId": "cla_energyunit", "Title": "Energy Systems and Solutions", "Rank": null, "Description": null, "Collection": "CurricularUnit", "Children": [ { "CurriculumId": "cla_lesson1_energyproblem", "Title": "The Energy Problem", "Rank": 1, "Description": null, "Collection": "Lesson", "Children": [ { "CurriculumId": "cla_activity1_energy_intelligence", "Title": "Energy Intelligence Agency", "Rank": 1, "Description": "A short game in which students find energy facts among a variety of bogus clues.", "Collection": "Activity", "Children": [] } … additional child activities are not shown here for brevityHere you can see that the unit titled Energy Systems and Solutions has a child lesson titled The Energy Problem, which itself has a child activity titled Energy Intelligence Agency. Since this structure represents the hierarchy explicitly, it is generally a lot faster to extract hierarchical relationships from it than from a table which represents the hierarchy implicitly by means of independent parent-child relationships.
Educational Standards are also handled differently in TE 2.0. As noted earlier, curriculum resources in TE 1.0 only stored the identifiers of the standards to which the resource was aligned. In TE 2.0, all of the properties necessary to render a standard alignment on a curriculum page are included in the JSON representation of the curriculum resource. As discussed in chapter 4, it can sometimes be advantageous to de-normalize data in a database. This is an example of such a case. Since standards do not change once they are published by the standard’s creator, we do not need to worry about having to update the details of a standard in every resource which is aligned to that standard. In addition, storing the standards with the curriculum resource boosts performance by eliminating the need for additional queries to retrieve standard details. Whereas this implies a lot of duplication of standard data in the database, the significant speed gain in extracting the resource-standard relationships is well worth the extra storage. The following is an example of the properties of a standard that are embedded in a curriculum resource.
"EducationalStandards": [ { "Id": "http://asn.jesandco.org/resources/S2454426", "StandardsDocumentId": "http://asn.jesandco.org/resources/D2454348", "AncestorIds": [ "http://asn.jesandco.org/resources/S2454504", "http://asn.jesandco.org/resources/S2454371", "http://asn.jesandco.org/resources/D2454348" ], "Jurisdiction": "Next Generation Science Standards", "Subject": "Science", "ListId": null, "Description": [ "Biological Evolution: Unity and Diversity", "Students who demonstrate understanding can:", "Construct an argument with evidence that in a particular habitat some organisms can survive well, some survive less well, and some cannot survive at all." ], "GradeLowerBound": 3, "GradeUpperBound": 3, "StatementNotation": "3-LS4-3", "AlternateStatementNotation": "3-LS4-3" } ]
While the resource accessioning experience in TE 2.0 is more streamlined and user friendly, it does have a downside. In TE 1.0, if a property was added to a curriculum resource, updating the XML schema was the only step needed to allow taggers to utilize the new property. This was because the Authentic tool would recognize the Schema change and the editing experience would automatically adjust. In TE 2.0, adding a field requires a software developer to make code changes to the edit interface. On balance, however, since resource schemas do not change that often, the advantages of a (much) more user-friendly resource editing experience outweigh the occasional need for code changes.
- The term tagger stems from the TE 1.0 period during which document conversion consisted of embedding content in XML ‘tags.’ ↵
- The S* standard identifiers are maintained by the Achievement Standard Network project. They can be viewed using the following URL: http://asn.desire2learn.com/resources/S*_code_goes_here ↵
