A Word on robots.txt
The robots.txt file, when inserted into the root of the web server’s file system, can be used by web designers and administrators to communicate instructions to robot software on how to behave. For instance, web administrators may wish to exclude certain pages from being visited by robots or may want to instruct robots to wait a certain amount of time before making any subsequent requests.
Instructions in the robot.txt file follow the so-called robot exclusion protocol or robot exclusion standard developed by Martijn Koster in 1994. Although the protocol is not part of an official standard or RFC, it is widely used on the web.
Why do we care to provide instructions to robots visiting our web pages? Well, we generally welcome those robots which, by extracting information from our pages, may give back to us in the form of high rankings in search engines; e.g., Googlebot and Bing. Yet, we often want to prevent even these welcome robots from visiting certain sections of our web site or specific types of information. For instance, we might have a set of web pages which are exclusively for administrative use and we do not want them to be advertised to the rest of the world. It may be fine to have these pages exposed to the world for some time without enforcing authentication protocols, but we just do not want them advertised on Google. Similarly, we might, at one time or other, decide that an existing set of pages should no longer be indexed by search engines. It might take us some time, however, to take the pages down. Instructing robots in the meantime not to access the pages might just do the trick.
Naturally, the rules and instructions coded in a robots.txt file cannot be enforced and thus, compliance is entirely left to the robot and hence, its programmer. ‘Good’ robots always first request the robots.txt file and then follow the rules and directives coded in the file. Most (but not all) ‘bad’ or ‘ill-behaved’ robots —the ones which do not behave according to the rules of the robots.txt file— do not even bother to request the robots.txt file. Hence, a quick scan of your web server log to see which robots requested the file is a good (although not perfect) indication of the set of ‘good’ robots issuing requests to your site.
The two most important directives typically used in a robots.txt file are the User-Agent and Disallow directives. The User-Agent directive is used to specify the robots to which the other directive(s) are directed. For instance, the directive
User-Agent: *
indicates ‘all robots,’ whereas the directive
User-Agent: googlebot
specifies that the directives apply to googlebot.
Different directives can be specified for different robots. For instance, the content:
User-agent: googlebot Disallow: /private/ User-agent: bing Disallow: /
disallows googlebot the private directory whereas bing is disallowed the whole site.
Googlebot is a pretty ‘good’ robot, although it ignores certain types of directives. It ignores, for instance, the Crawl-delay directive which can be used to specify time (in seconds) between requests, but at least it says so explicitly and publicly in its documentation.
Let us take a look at TE 2.0’s robots.txt file.
# This is the production robots.txt file User-agent: * Crawl-delay: 2 Disallow: /standards/browse Disallow: /curriculum/print/* Disallow: /view_lesson.php?* Disallow: /view_curricularunit.php?* Disallow: /view_activity.php?* Disallow: /search_results.php?* Sitemap: https://www.teachengineering.org/sitemap.xml
The items other than the User-agent and Crawl-delay items, need some explanation. For instance, why are there references to PHP pages; e.g., view_lesson.php or view_activity.php, especially since in previous chapters we stated that whereas TE 1.0 was written in PHP, TE 2.0 does not have any PHP (it is all in C#)?
The reason for these odd references and for requesting robots not to crawl them, is that when TE 2.0 was launched, it was ―and still is― very likely that other websites contained links to these TE 1.0 pages. Hence, we kept these pages functional in that they can be requested but those requests are then redirected to the TE 2.0 version of them. This is an important point. Far too often do we see websites make URL changes which render all their old URLs invalid, thereby invalidating any and all the links to the old pages maintained by the rest of the world. A far better and much friendlier way of handling URL migration is to redirect the requests for the old URLs to the new URLs; at least for some reasonable amount of time, so that the linking websites have some time to reset their links.
To see this URL redirecting at work, pull up the https://www.teachengineering.org/sitemap.xml page in your web browser (this may take few seconds), and click on one of the follow-up *.xml links. Note how this results in a long list of TE 2.0 URL pages.
Keeping those old URLs up, however, implies a real risk that robots continue to crawl them, which is what we do not want. Therefore, whereas the old URLs continue to function, the robot.txt file instructs the robots not to crawl/use them (Disallow:). Interestingly, no Disallow directive is specified for https://www.teachengineering.org/sitemap.xml. The reason, of course, is that following the links on that page eventually leads to TE 2.0 URLs, so there is no problem with letting robots crawl that page.
Detecting Robots
Robots also can be a drain on data communications, data retrieval and data storage bandwidth. About 2/3 of all HTTP requests TeachEngineering 1.0 received originated from robots. Hence, we might benefit (some) from limiting the ‘good’ robots from accessing data we do not want them to access, thereby limiting their use of bandwidth. Of course, for the ‘bad’ robots the robots.txt method does not work and we must resort to other means such as blocking or diverting them rather than requesting them not to hit us.
Regardless of whether or not we want robots making requests to our servers, we might have good reasons for at least wanting to know if robots are part of the traffic we serve and if so, who and what they are and what percentage of the traffic they represent:
- We might want to try and separate humans ―you know, the creatures which Wikipedia defines as “…a branch of the taxonomical tribe Hominini belonging to the family of great apes”― from robots, simply because we want to know how human users use our site.
- We might want to know what sort of burden; e.g., demand on bandwidth, robots put on our systems.
- We might just be interested to see what these robots are doing on our site.
- Etc.
We can try separating robots from humans either in real time; i.e., as the requests come in, or after the fact. If our goal is to block robots or perhaps divert them to a place where they do not burden our systems, we must do it in real-time. Oftentimes, however, separation can wait until some time in the future; for instance when generating periodic reports of system use. In many cases a combination of these two approaches is used. For instance, we can use periodic after-the-fact web server log analysis to discover the robots which visited us in a previous period and use those data to block or divert these robots real-time in future.
Real-time Robot Detection
Several methods for real-time robot detection exist:
- JavaScript-based filtering. Robots typically (although not always!) do not run/execute the JavaScript included in the web pages they retrieve. JavaScript embedded in web pages is meant to be executed by/on the client upon retrieval of the web page. Whereas standard web browsers try executing these JavaScript codes, very few robots do. This is mostly due to the fact that the typical robot is not after proper functionality of your web pages, but instead is after easy-to-extract information such as the content of specific HTML or XML tags such as the ones containing web links. Hence, we can make use of snippets of JavaScript code which will most likely only be executed by browsers driven by humans. This is, for instance, one reason why the hit counts collected by standard Google Analytics accounts contain very few if any robot hits. After all, to register a hit on your web page with Google Analytics, you include a snippet of JavaScript in your web page containing the registration request. This snippet, as we just mentioned, is in JavaScript and hence, is typically not executed by robots.
- Real-time interrogation. Sometimes we just want to be very confident that a human is on the other end of the line. This is the case, for instance, when we ask for opinions, customer feedback or sign-up or confidential information. In such cases, we might opt to use a procedure which in real-time separates the humans from the machines, for instance by as asking the requester to solve a puzzle such as arranging certain items in a certain way or recognizing a particular pattern. Of course, as machines get smarter at solving these puzzles, we have to reformulate the puzzles. A good example is Google’s moving away some time ago from a puzzle which asked requesters to recognize residential house numbers on blurry pictures. Whereas for a while this was a reliable human/machine distinguishing test, image-processing algorithms have become so good that this test is no longer sufficient.
- Honeypotting. Another way of recognizing robots in real-time is to set a trap into which a human would not likely step. For instance, we can include an invisible link in a web page which would not likely be followed by a human but which a robot which follows all the links on a page ―a so-called crawler or spider― would blindly follow.
We successfully used this technique in TE 1.0 where in each web page we included an invisible link to a server-side program which, when triggered, would enter the IP address of the requester in a database table of ‘suspected’ IPs. Every month, we would conduct an after-the-fact analysis to determine the list of (new) robots which had visited us that month. The ones on the ‘suspect’ list were likely candidates. Once again, however, there is no guarantee since nothing prevents an interested individual to pull up the source code of an HTML page, notice the honeypot link and make a request there, just out of curiosity. - Checking a blacklist. It may also be possible to check if the IP of an incoming request is included in one or more blacklists. Consulting such lists as requests come in may help detecting out returning robots. Blacklists can be built up internally. For instance, one of the products of periodic in-house after-the-fact robot detection is a list of caught-in-the-act robots. Similarly, one can check IPs against blacklisted ones at public sites such as http://www.projecthoneypot.org/
Of course, checking against blacklists takes time and especially if this checking must be done remotely and/or against public services, this might not be a feasible real-time option. It is, however, an excellent option for after-the-fact robot detection.
After-the-fact Robot Detection
Just as for real-time robot detection, several after-the-fact ―ex post if you want to impress your friends― robot detection methods exist.
- Checking a blacklist. As mentioned at the end of the previous section, checking against blacklists is useful. If the IP address has been blacklisted as a robot or bad robot, it most likely is a robot.
- Statistics. Since robots tend to behave different from humans, we can mine our system logs for telltale patterns. Two of the most telling variables are hit rates and inter-arrival times; i.e., the time elapsed between any two consecutive visits by the same IP. Robots typically have higher hit rates and more regular inter-arrival times than humans. Hence, there is a good chance that at the top of a list sorted by hit count in descending order, we find robots. Similarly, if we compute the variability; e.g., the standard deviation of inter-arrival times and we sort that list in ascending order ―smallest standard deviations at the top― we once again find the robots at the top. Another way of saying this is that since robots tend to show very regular or periodic behavior, we should expect to see very regular usage patterns.
Thought Exercise
Here we explore this statistical approach for a single month; i.e., April 2016 of TE 1.0 usage data. Assume a table in a (MySQL) relational database called april_2016_hits. Assume furthermore that from that table we have removed all ‘internal’ hits; i.e., all hits coming from inside the TeachEngineering organization. The april_2016_hits table has the following structure:
| Field | Type | Nullability | Key |
|---|---|---|---|
| id | int(11) | no | primary |
| host_ip | varchar(20) | no | – |
| host_name | varchar(256) | yes | – |
| host_referer | varchar(256) | yes | – |
| file | varchar(256) | no | – |
| querystring | varchar(256) | yes | – |
| username | varchar(256) | yes | – |
| timestamp | datetime | no | – |
-
- Find the total number of hits:
select count(*) from april_2016_hits;
777,018
- Find the number of different IPs:
select count(distinct(host_ip)) from april_2016_hits;
296,738
- Find the 15 largest hitters and their hit counts in descending order of hit count:
select host_ip, count(*) as mycount from april_2016_hits group by host_ip order by mycount desc limit 15;
Figure 1: 15 largest April 2016 hitters and their hit counts. IP Hit count – 106.38.241.111 76.8.237.126
52.207.222.53
161.97.140.2
199.15.233.162
52.10.17.20
70.32.40.2
54.208.169.126
96.5.120.250
96.5.121.250
192.187.119.186
69.30.213.82
52.11.40.118
107.152.3.27
52.91.70.160
4007 2065
1342
1265
1051
1034
969
934
933
893
792
772
766
733
696
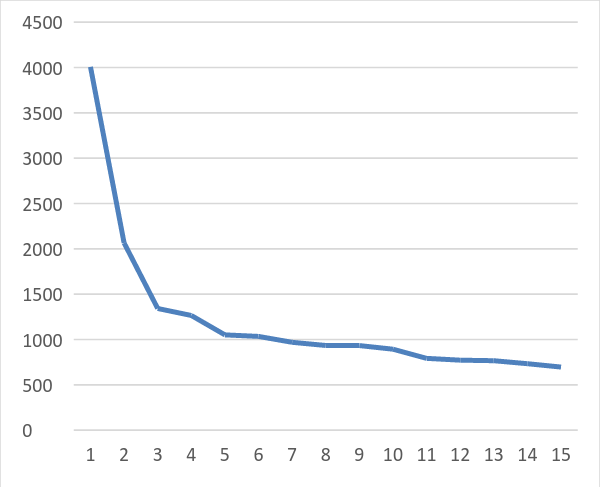
Notice the exponential pattern (Figure 1).
- Let us first see if we can track these top two IPs down a bit (https://whatismyipaddress.com/ip-lookup):
- 106.38.241.111: CHINANET-BJ, Beijing, China. projecthoneypot.org flags this IP as a likely robot (possible harmless spider)
- 76.8.237.126: TELEPAK-NETWORKS1, C-Spire Fiber, Ridgeland, MS. projecthoneypot.org does not have data on this IP.
- Next, let us take a look at the hit patterns. The first 100 timestamps by 106.38.241.111 in April 2016:
select timestamp from april_2016_hits where host_ip = '106.38.241.111' order by timestamp desc limit 100; --(The inter-arrival times were computed from the data returned from the database query)
Table 2: IP Address Hit Patterns Day Time Inter-arrival time Inter-arrival time (secs) 4/8/2016 11:29:47 4/8/2016 11:31:53 0:02:06 126 4/8/2016 11:33:04 0:01:11 71 4/8/2016 11:36:24 0:03:20 200 4/8/2016 11:37:33 0:01:09 69 4/8/2016 11:38:42 0:01:09 69 4/8/2016 11:39:50 0:01:08 68 4/8/2016 11:41:00 0:01:10 70 4/8/2016 11:42:09 0:01:09 69 4/8/2016 11:43:20 0:01:11 71 4/8/2016 11:45:44 0:02:24 144 4/8/2016 11:46:52 0:01:08 68 4/8/2016 11:48:02 0:01:10 70 4/8/2016 11:49:12 0:01:10 70 4/8/2016 11:50:25 0:01:13 73 4/8/2016 11:51:33 0:01:08 68 4/8/2016 11:52:43 0:01:10 70 4/8/2016 11:53:51 0:01:08 68 4/8/2016 11:55:02 0:01:11 71 4/8/2016 11:57:46 0:02:44 164 4/8/2016 11:58:54 0:01:08 68 4/8/2016 12:00:09 0:01:15 75 4/8/2016 12:01:24 0:01:15 75 4/8/2016 12:02:36 0:01:12 72 4/8/2016 12:03:48 0:01:12 72 4/8/2016 12:05:00 0:01:12 72 4/8/2016 12:07:19 0:02:19 139 4/8/2016 12:08:32 0:01:13 73 4/8/2016 12:09:42 0:01:10 70 4/8/2016 12:10:52 0:01:10 70 4/8/2016 12:12:04 0:01:12 72 4/8/2016 12:13:18 0:01:14 74 4/8/2016 12:15:40 0:02:22 142 4/8/2016 12:16:47 0:01:07 67 4/8/2016 12:17:55 0:01:08 68 4/8/2016 12:19:03 0:01:08 68 4/8/2016 12:20:12 0:01:09 69 4/8/2016 12:21:22 0:01:10 70 4/8/2016 12:22:38 0:01:16 76 4/8/2016 12:23:46 0:01:08 68 4/8/2016 12:24:59 0:01:13 73 4/8/2016 12:27:14 0:02:15 135 4/8/2016 12:28:23 0:01:09 69 4/8/2016 12:33:00 0:04:37 277 4/8/2016 12:34:08 0:01:08 68 4/8/2016 12:37:29 0:03:21 201 4/8/2016 12:38:41 0:01:12 72 4/8/2016 12:39:48 0:01:07 67 4/8/2016 12:40:56 0:01:08 68 4/8/2016 12:42:05 0:01:09 69 When studying the inter-arrival times; i.e., the time periods between hits, we notice that at least in the first 100 hits, there are no hits within the same minute. When checked over the total of 4,007 hits coming from this IP, we find only 46 hits (1.1%) which occur within the same minute and we find no more than two such hits in any minute. Such a regular pattern is quite unlikely to be generated by humans using the TeachEngineering web site. Moreover, the standard deviation of the inter-arrival times (over the first 100 hits) is 38.12 seconds, indicating a very periodic hit frequency. When we remove the intervals of 100 seconds or more, the standard deviation reduces to a mere 2.66 seconds and the mean inter-arrival time becomes 70.46 seconds.
Finally, Figure 2 shows a histogram of the inter-arrival times for the first 100 hits. It indicates regular clustering at multiples of 70 seconds (70, 140, 210 and 280 seconds).
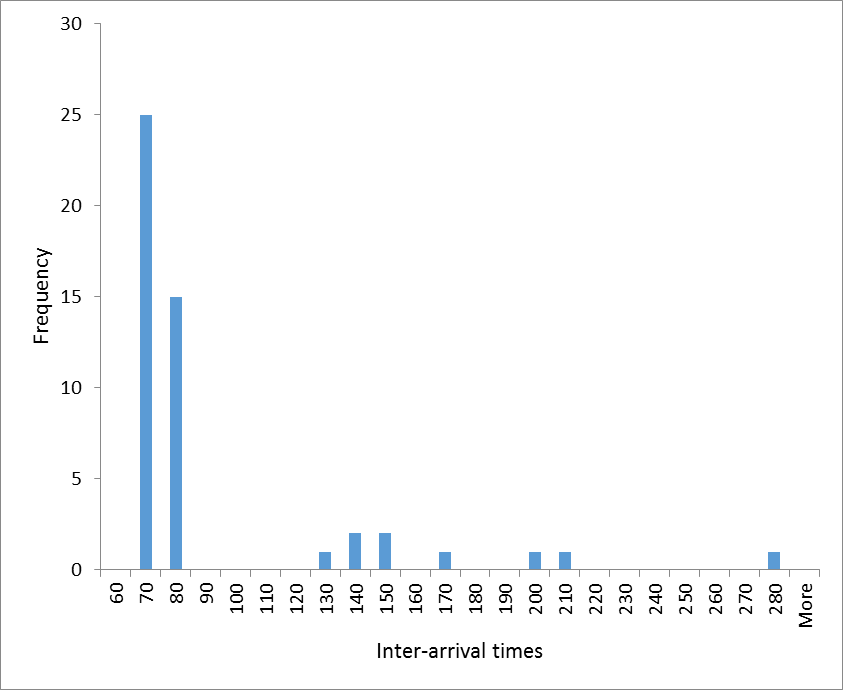
Figure 2: histogram of the inter-arrival times for the first 100 hits by IP 106.38.241.111. These data indicate a very periodic behavior which makes intra-minute hits very rare indeed. From these data, plus the fact that this IP has been flagged by projecthoneypot.org, it is reasonable to conclude that this IP represented a robot.
- For IP 76.8.237.126 we find the following distribution of hits over the days in April:
select day(timestamp), count(*) from april_2016_hits where host_ip = '76.8.237.126' group by day(timestamp) order by day(timestamp);
Distribution of Hits Day (date) Table 3: Hit count 1 1 4 9 5 1436 6 577 7 2 8 1 11 10 12 2 13 8 14 1 15 6 19 10 22 2 We notice that 97.5% (1,436 + 577) / 2065) of this IP’s activity occurred on just two days: April 5th and 6th.
Looking at the 1,436 hits for April 5th, we find a mean inter-arrival time of 18.39 seconds and an inter-arrival time standard deviation of 194 seconds. This is odd. Why the high standard deviation? Looking through the records in the spreadsheet (not provided here) we find five pauses of 1000 seconds or more. After eliminating these, the mean drops to 8.14 seconds and the standard deviation reduces to a mere 16 seconds.
These data are compatible with at least two scenarios:
- A robot/spider/crawler which either pauses a few times or which gets stuck several times after which it gets restarted.
- A two-day workshop where (human) participants connect to TeachEngineering through a router or proxy server which, to the outside world, makes all traffic appear as coming from a single machine.
Looking a little deeper, the 1,000+ second pauses mentioned above appeared at typical workday break intervals: 8:00-9:00 AM, 12:00-1:00 PM, etc.
At this point we looked at the actual requests coming from this IP to see if these reveal some sort of pattern we can diagnose. We retrieved a list of requests, over both days in April, ordered by frequency:
select file, count(*) from april_2016_hits where host_ip = '76.8.237.126' and (day(timestamp) = 5 or day(timestamp) = 6) group by file order by count(*) desc;
The results are telling:
Table 4: Requests and Frequencies
File Hit count /livinglabs/earthquakes/socal.php 1034 /index.php 476 /livinglabs/earthquakes/index.php 395 /livinglabs/index.php 30 /view_activity.php 29 /livinglabs/earthquakes/sanfran.php 8 /livinglabs/earthquakes/japan.php 6 /livinglabs/earthquakes/mexico.php 6 /browse_subjectareas.php 4 /browse_lessons.php 4 /googlesearch_results_adv.php 4 /login.php 3 /whatisengr.php 2 /whyk12engr.php 2 /history.php 2 /ngss.php 2 /browse_curricularunits.php 2 /search_standards.php 1 /about.php 1 /view_lesson.php 1 /googlesearch_results.php 1 The vast majority of requests are associated with a very specific and small set of TeachEngineering activities, namely the Earthquakes Living Lab, with more than 40% of the hits requesting the home pages of TeachEngineering (index.php) and the Earthquakes lab (/livinglabs/earthquakes/index.php). Whereas this is not your typical robot behavior, it is quite compatible with a two-day workshop on earthquake-related content where people come back to the system several times through the home page, link through to the Earthquakes Lab and take things from there.
- Find the total number of hits:
