5

Chapter 5
Monolith versus Microservice Architectures
High-level architecture is the software’s all-encompassing code design. When described with a diagram, a high-level architecture usually looks like a few to dozens of interconnected shapes with short labels, an abstraction that usually represents the entire codebase. In this chapter, we’ll use “architecture” interchangeably with “high-level architecture” (in other contexts, software architecture can refer to code design at lower levels).
In this chapter, I won’t be covering every high-level architecture. Instead, I’ll concentrate on two distinct high-level architectures: monolith and microservices. Talking about the ways they’re different will lead us through concepts applicable to high-level architecture in general.
5.1 Monolith Architecture
Monolith software is one interconnected codebase that cannot easily be divided into multiple independent components that run separately and are individually useful.
If you’re trying to think of an example of a monolith and nothing is coming to mind, that’s probably because this architecture is so common that it can arise without having to plan. Your first computer program was probably a small monolith. If you keep adding more code/files/classes/components, the software becomes a bigger monolith—unless you change the architecture.
5.2 Microservice Architecture
Microservices are separate applications, each of which runs in a separate process and could be individually useful. This section describes core characteristics of software that uses the microservice architecture. The subheadings are borrowed from Lewis & Fowler (2014). Martin Fowler’s Microservices Guide (Fowler, 2019) provides additional discussion.
5.2.1 “Smart End Points and Dumb Pipes”
The communication pipe within a microservice architecture is simple, and the services themselves take care of translating and otherwise processing messages. For example, microservices commonly communicate through a REST API, which allows these kinds of messages: GET, POST (create), PUT (update), or DELETE. The contents of the messages can be complex, but it’s the job of the services to deal with that.
5.2.2 “Componentization via Services”
In a microservice architecture, components are services. The Lewis and Fowler (2014) definition of a component is “a unit of software that is independently replaceable and upgradeable.” A service provides functionality while running in its own process. A monolith typically has code with tight coupling and components that run in the same process.
Advantages of splitting components into services:
- Independence: Each individual service can be updated, tested, launched, and stopped without requiring the same from other components of the software. In contrast, with some monolithic software, all tests must be run each time a developer commits to a change, which can make for a long wait. If a service fails, any software depending on it will be without that service, but the rest of the software needn’t be affected.
- Standardized component communication: Service communication pipes can be simple and the same each time. This can make for less thinking, fewer mistakes, and less violation of encapsulation when connecting two components—just use the pipe.
Disadvantages of splitting components into services:
- More expensive communication: Components in a monolith can communicate via direct calls (fast, lightweight); in contrast, microservices often communicate over a network. Microservice requests typically need to include request metadata, and because the pipes are “dumb,” responses might contain extra data (slower, heavier).
- Potentially less secure communication: Communication over a network can be more prone to interception and alteration.
5.2.3 “Organized around Business Capabilities”
You may have heard of the client-server architecture, in which multiple instances of client-side software communicate with server-side software, which communicates with a database. That architecture is organized around technology. Another way to put that: someone unfamiliar with the differences between client-side software, server-side software, and a database would not get much out of seeing a diagram of this architecture.
In contrast, microservices are organized around business capabilities. This term has multiple definitions. Michell’s (2011) integrated definition of a business capability fits what we’re talking about: “the potential of a business resource (or groups of resources) to produce customer value by acting on their environment via a process using other tangible and intangible resources.”
Examples of business capabilities:
- The manufacturer can slice a 20-foot by 40-foot rectangle of wheat dough into 0.5-cm strips in 1.2 seconds, which will later become packaged noodles someone can buy for lunch in a grocery store.
- A loan officer can lead a customer through the process of securing a loan, enabling the customer to start a small business.
- A pet food distributor can regularly ship nutritionally balanced cat food to stores around the country.
- The software can make a video file compatible with mobile devices.
One implication of being focused on business capabilities is that each microservice can have its own tech stack (including its own database).
5.2.4 “Decentralized Data Management”
In a microservice architecture, each service typically has its own database instead of sharing a centralized database. This is part of decoupling the software’s components, which has many benefits including failure containment. A disadvantage is that if two microservices need to share data, the two copies of that data can become inconsistent (e.g., because one database has not yet received the update). Microservice databases are said to have eventual consistency, which means that, with time, each microservice will have the most up-to-date information, but meanwhile, there could be a mismatch (perhaps one that will annoy or mislead human users).
5.2.5 “Decentralized Governance”
Microservices need only be compatible at their interfaces (communication pipe), leaving flexibility in how each is implemented. For example, each service can be written in a different language, reducing the weight of tech stack decisions and decreasing the need to compromise on those decisions. For each service, teams can choose the optimal programming language, framework, architecture, and more. The technologies of each microservice can be independently changed. Conversely, in a monolith, teams might only need to maintain a small set of technologies (e.g., if there’s only one framework, only one framework will need updates installed) and might not need as broad of expertise (e.g., having working knowledge of five programming languages). Also, when code is more or less part of the same codebase, it might be easier to maintain the same standards across the code.
5.2.6 “Design for Failure”
When services run in different processes on different machines and were created by different teams using different technologies and standards, that can change how developers think. Instead of keeping the whole ship afloat, thinking can shift toward service-specific monitoring, logging, and design decisions about what to do when a service fails—including what to tell the user. In contrast, with a monolith, more thought might be put into how to revert quickly if a deployment fails (because failure might mean no part of the monolith works). Monoliths can also be designed for failure, but that’s not as natural a tendency as with microservices.
5.3 Monolith Compared to Microservices
This section recaps and expands upon differences between monolith and microservice architectures (Fowler, 2015; Lewis & Fowler, 2014).
5.3.1 How Does Communication Happen within a Monolith versus between Microservices?
In a monolith, communication (e.g., between classes and components) can happen in many ways, including through direct calls and over a network. With microservices, communication typically happens over a network such as through HTTP requests/responses, through “dumb,” standardized communication pipes. While microservices communication pipes are less complex, that means the end points need to be smarter. Also, communication over a network can be less reliable and less secure.
5.3.2 How Is a Monolith Deployed versus Microservices?
Monolithic software often needs to be deployed all at once. Microservices can be independently deployed and can potentially be stopped without stopping connected services.
5.3.3 How Is a Monolith Scaled versus Microservices?
If your monolithic software needs more resources to be able to support how much it’s being used, it can be copied onto multiple machines. Each machine must have enough space, memory, processing speed, and the like to support the entire monolith.
If your microservices software needs more resources, you have more options. For example, the services that are used more can be replicated more times.
5.3.4 How Is a Monolith Tested versus Microservices?
In microservice software, each service can be independently tested. In a monolith, the way you test is influenced by dependencies within the code, which could reach broadly across the software (and make for slow tests).
5.3.5 How Is a Monolith Upgraded versus Microservices?
Each microservice can be written in a different language (e.g., one in Python, another in Java, another in C++, etc.) and can run in different contexts (e.g., machines with different operating systems, libraries, versions of libraries, and so on). In theory, this means they can be independently upgraded.
With a monolith, upgrading may require more care. Each component must be compatible with the new context (but this is also sometimes true with microservices).
5.3.6 How Is the Database Used in a Monolith versus Microservices?
Monolithic software might have just one database, potentially a very large one. This can create a bottleneck if multiple parts of the software need to access the database in parallel and can make for slow database backups/restores, among other drawbacks. If you only have one database, however, that’s just one place for managing database access accounts and one database to maintain/back up/restore/etcetera. In contrast, each microservice typically has its own data storage.
5.4 Summary
Monolith and microservice architectures have different advantages and disadvantages. In a microservice architecture, each service is its own application and can be independently managed. Communication mechanisms between modules can be standardized. In a monolith, however, the codebase can be deployed all at once and components can communicate directly, which can be more reliable, less expensive, and provide better consistency than communicating between multiple applications over a network.
5.5 Case Study: Microservice Architecture
The Oregon State University (OSU) Center for Applied Systems and Software (CASS) is a nonprofit that gives students real-world software development experience through its work with clients such as the Oregon Department of Transportation (ODOT).
CASS and ODOT decided to convert ODOT’s statewide computer-aided dispatch software, Transportation Operation Center System (TOCS), from a monolith to microservices. TOCS helps dispatchers share road emergency information with responders and the public. The part of TOCS that CASS started with was the outdated home screen.
From a user perspective, the main problem with the TOCS home screen was inflexibility. Dispatcher centers in different parts of Oregon had different needs (e.g., some centers dealt with more icy roads, others withs more fender-benders) but had to use the same home screen, which could not be easily configured.
From a developer perspective, the monolith had multiple technological drawbacks that made it difficult to respond to TOCS users’ needs:
- It was difficult to keep software components decoupled, especially since many different developers worked on the software. They were building up technical debt, which meant that developers might need to focus on clearing that debt instead of implementing new TOCS features.
- CASS could only deploy TOCS a few times a year because the software had to be tested and deployed in its entirety (a long process) and it was essential for the software to remain stable, especially during times of year with more weather and road hazards. This meant dispatch centers had to wait a long time for new features (e.g., individualized home screens).
- There was a lot of pressure on the database because the TOCS software at all the dispatch centers was transacting with the same database and causing performance issues.
- Technology choices were limited because every part of the software had to be compatible with the .NET Framework. Even worse, their technology stack was becoming deprecated because Microsoft stopped releasing updates to the .NET Framework after version 4.8. CASS chose the microservice architecture as a solution to all these problems.
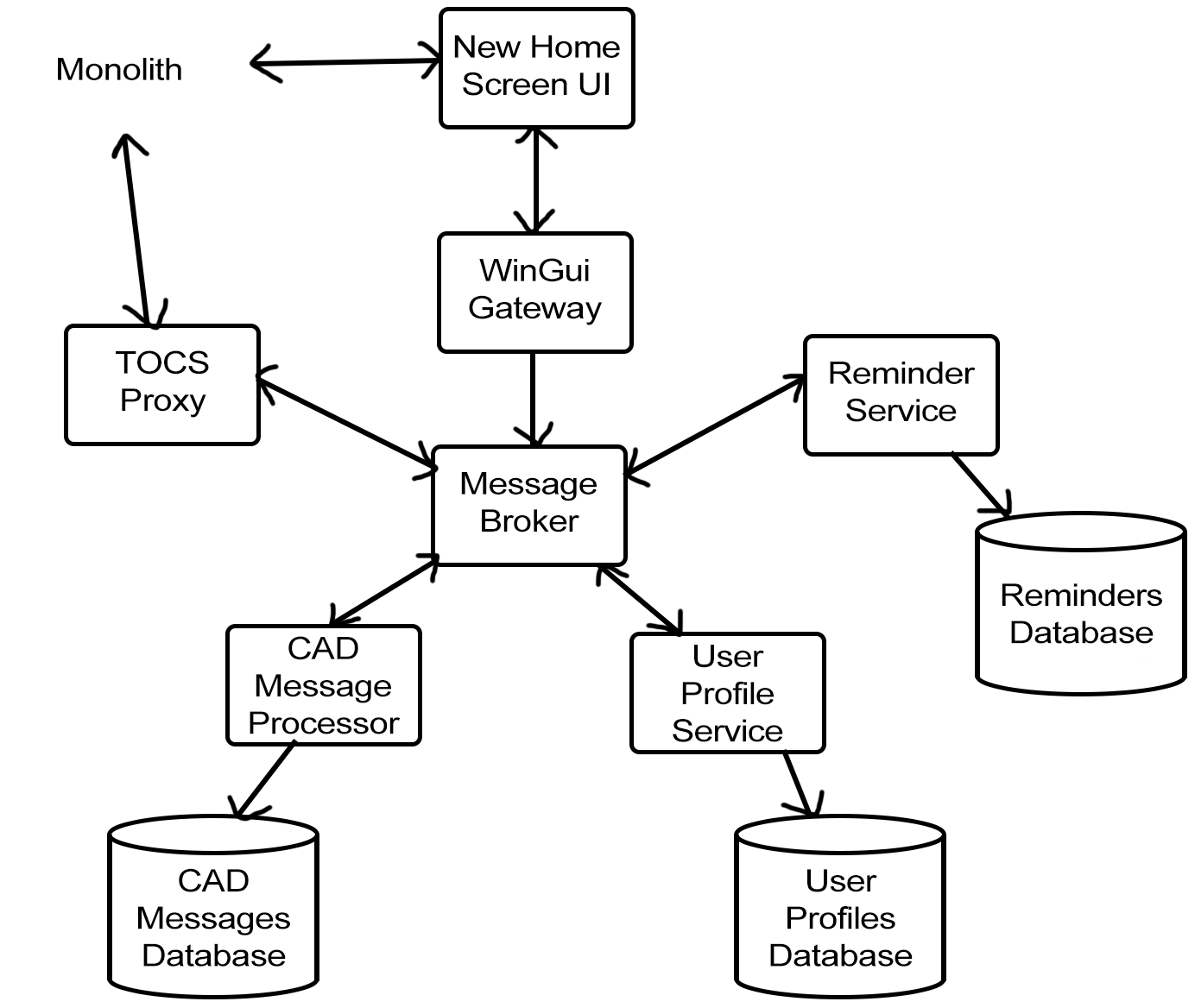
Figure 5.1 depicts the new architecture of the TOCS homepage, which integrates with the monolith. The WinGui Gateway application is responsible for preparing data from the services so it can be used by the New Home Screen UI. It uses the .NET 6 stack, which gives developers access to modern features. The Message Broker (Apache ActiveMQ) application talks to the services and the Gateway. Because the Message Broker uses a standard protocol, AMQP, it would be feasible to change the Message Broker technology in the future. Each service is also a separate application and has its own database. CASS found that one advantage of a dedicated database was that they could use JSON for the Profile Service, which was more appropriate than the relational database used within the monolith.
For more information about this project, see Fern (2022) for a video that describes it in detail.
References
Fern, A. (2022). Tech Talk Tuesday: Lessons in real-world software: going from monolith to microservices. OSU MediaSpace. https://media.oregonstate.edu/media/t/1_ls3xsa6r
Fowler, M. (2015, July 1). Microservice trade-offs. martinfowler.com. https://martinfowler.com/articles/microservice-trade-offs.html
Fowler, M. (2019, August 21). Microservices guide. martinfowler.com. https://martinfowler.com/microservices/
Lewis, J., & Fowler, M. (2014, March 25). Microservices. martinfowler.com. https://martinfowler.com/articles/microservices.html
Michell, V. (2011). A focused approach to business capability. In B. Shishkov (Ed.), Proceedings of the First International Symposium on Business Modeling and Software Design, 105–113. Springer. https://doi.org/10.5220/0004459101050113
Abstract representation of overall code design; covers all parts of the software.
Code design. Can be shown at different levels of abstraction and detail.
High-level architecture characterized by being in one or few pieces; cannot be easily divided into components that run separately and are independently useful.
High-level architecture characterized by multiple independent components that each run in their own process and communicate between one another without direct access.
Lewis, J., & Fowler, M. (2014, March 25). Microservices. martinfowler.com. https://martinfowler.com/articles/microservices.html
Fowler, M. (2019, August 21). Microservices guide. martinfowler.com. https://martinfowler.com/microservices/
Technology and/or approach used for sending and receiving messages between processes.
Within a codebase, a unit of the code containing related functionality. Ideally, a component is both replaceable and reusable.
A unit of software that receives and fulfills requests.
The degree to which one unit of code is dependent on another.
In object-oriented programming, (1) combining data and the methods that act upon those data into one unit of code or (2) preventing external direct access to data within a unit of code.
High-level architecture characterized by one component (the server) responding to requests and providing resources while other components (clients) request those resources.
Michell, V. (2011). A focused approach to business capability. In B. Shishkov (Ed.), Proceedings of the First International Symposium on Business Modeling and Software Design, 105–113. Springer. https://doi.org/10.5220/0004459101050113
The capacity of a business resource or a combination of resources to generate value for customers by leveraging their environment through a process that involves both tangible and intangible resources. Source: Michell, V. (2011). A focused approach to business capability. In Proceedings of the First International Symposium on Business Modeling and Software Design, 105–113. University of Reading. https://doi.org/10.5220/0004459101050113
The set of programming languages, frameworks, and other technologies chosen or needed for implementing a piece of software.
Characteristic of software systems where different parts of the system can have less up-to-date information (e.g., state, data) than other parts, but the inconsistencies are temporary.
Fowler, M. (2015, July 1). Microservice trade-offs. martinfowler.com. https://martinfowler.com/articles/microservice-trade-offs.html
Time and resources you (or someone else) will need to spend on modifying your software in the future because of the poor decisions you’re making in the present.
A lightweight data-interchange format that is easy for humans to read and write. Source: JSON.org. (n.d.). Introducing JSON. https://www.json.org/json-en.html
Fern, A. (2022). Tech Talk Tuesday: Lessons in real-world software: going from monolith to microservices. OSU MediaSpace. https://media.oregonstate.edu/media/t/1_ls3xsa6r
